22.1 分析環境の構築 python ver
2026/04/17
0.1 Python
最近流行りのプログラミング言語です。
機械学習らへんからめっちゃ流行りだした。データサイエンティストに受けたのでそのへんのことが一通りできる。
0.1.1 Google Colaboratory
Googleの提供するコード実行環境。デフォルトでpythonが動く。
pythonを手元のpcにインストールするのが手間なのでこの環境を使います。
略してcolab (コラボ) と呼ぶことにします。
0.2 ノートブック
colabはgoogle driveの中のファイルとして存在します。
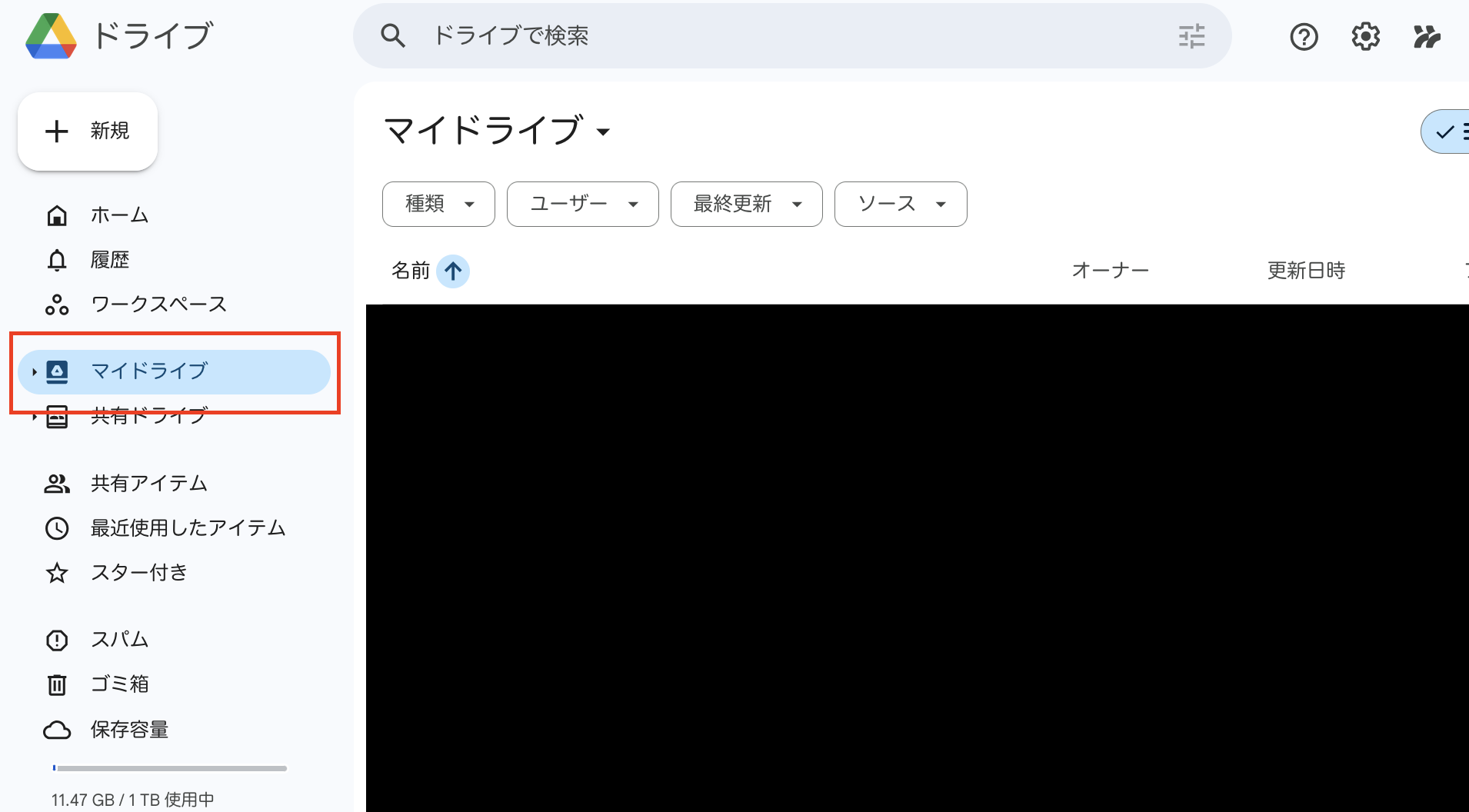
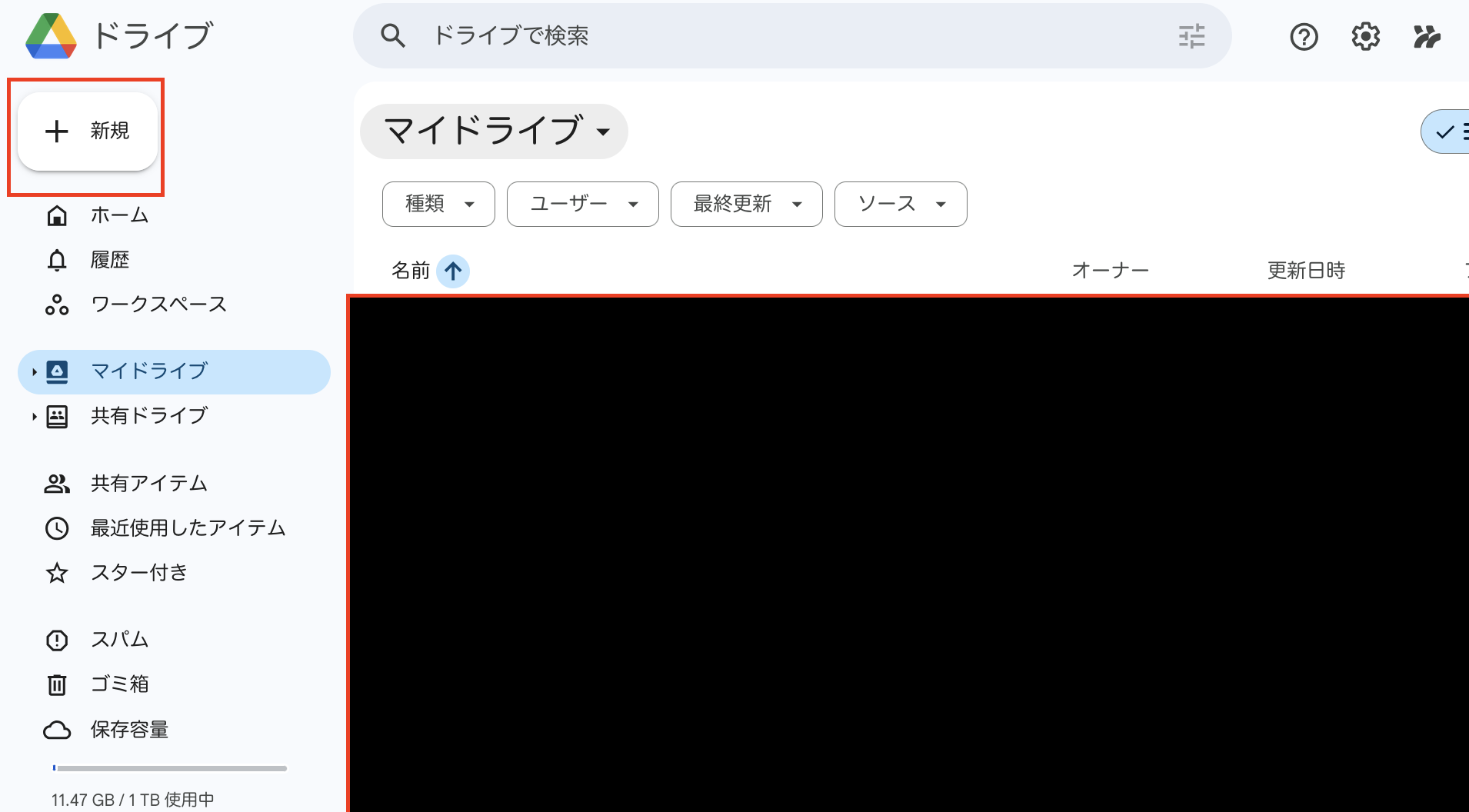
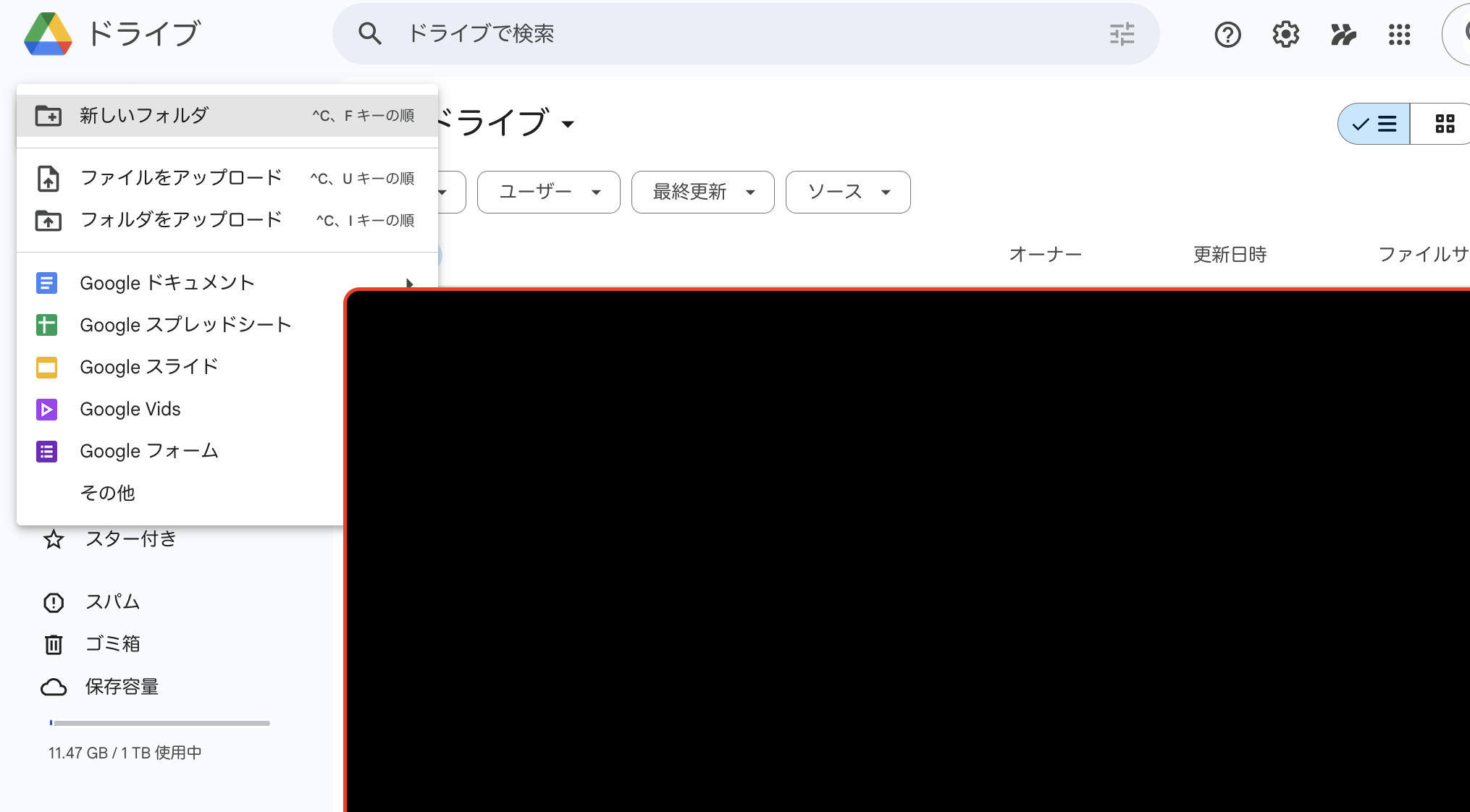
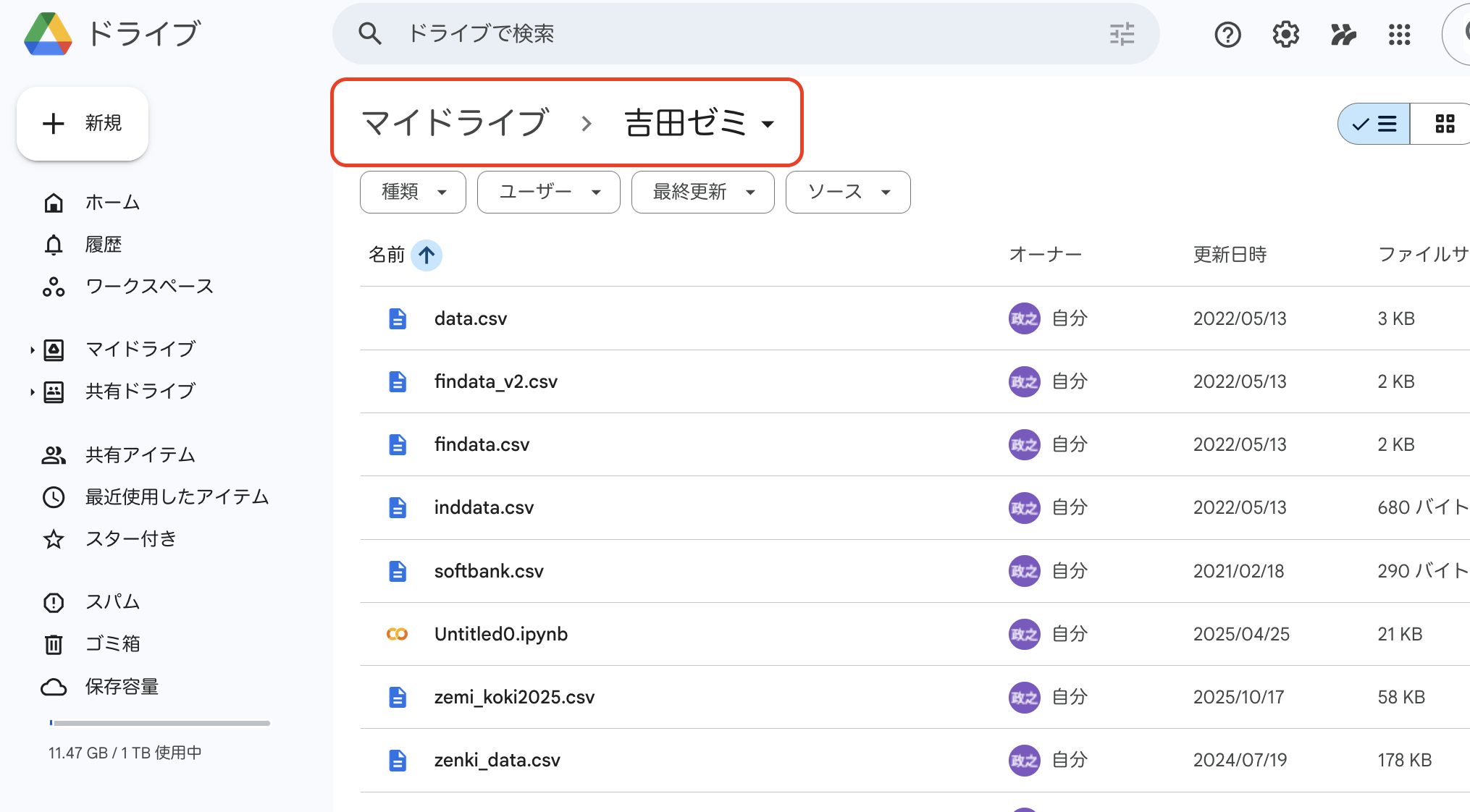
なので、まずはこのゼミのためのフォルダをgoogle drive上に作成します。
0.2.1 フォルダの作成とcolabを使えるようにするまで
ここの操作は初回のみ
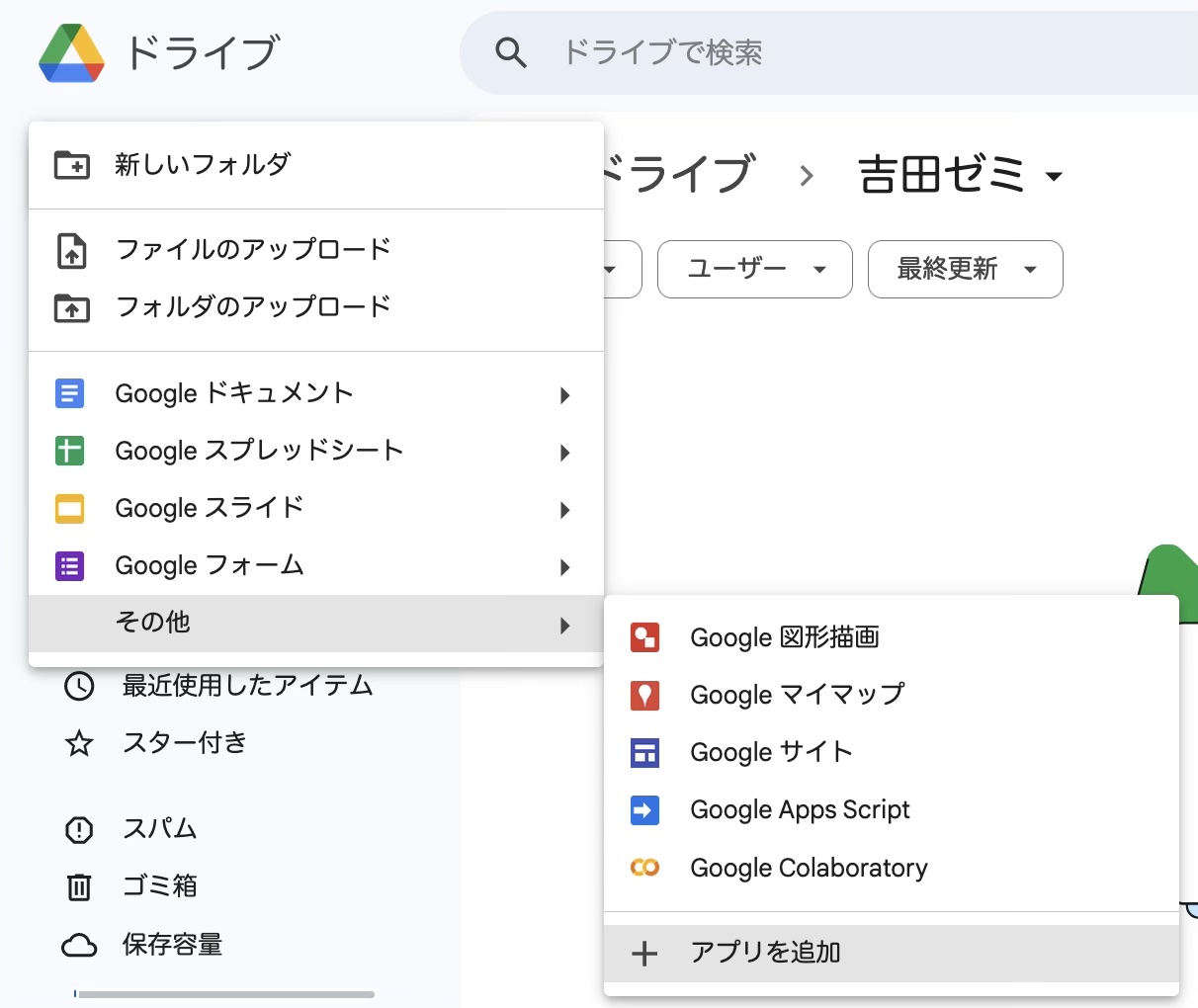
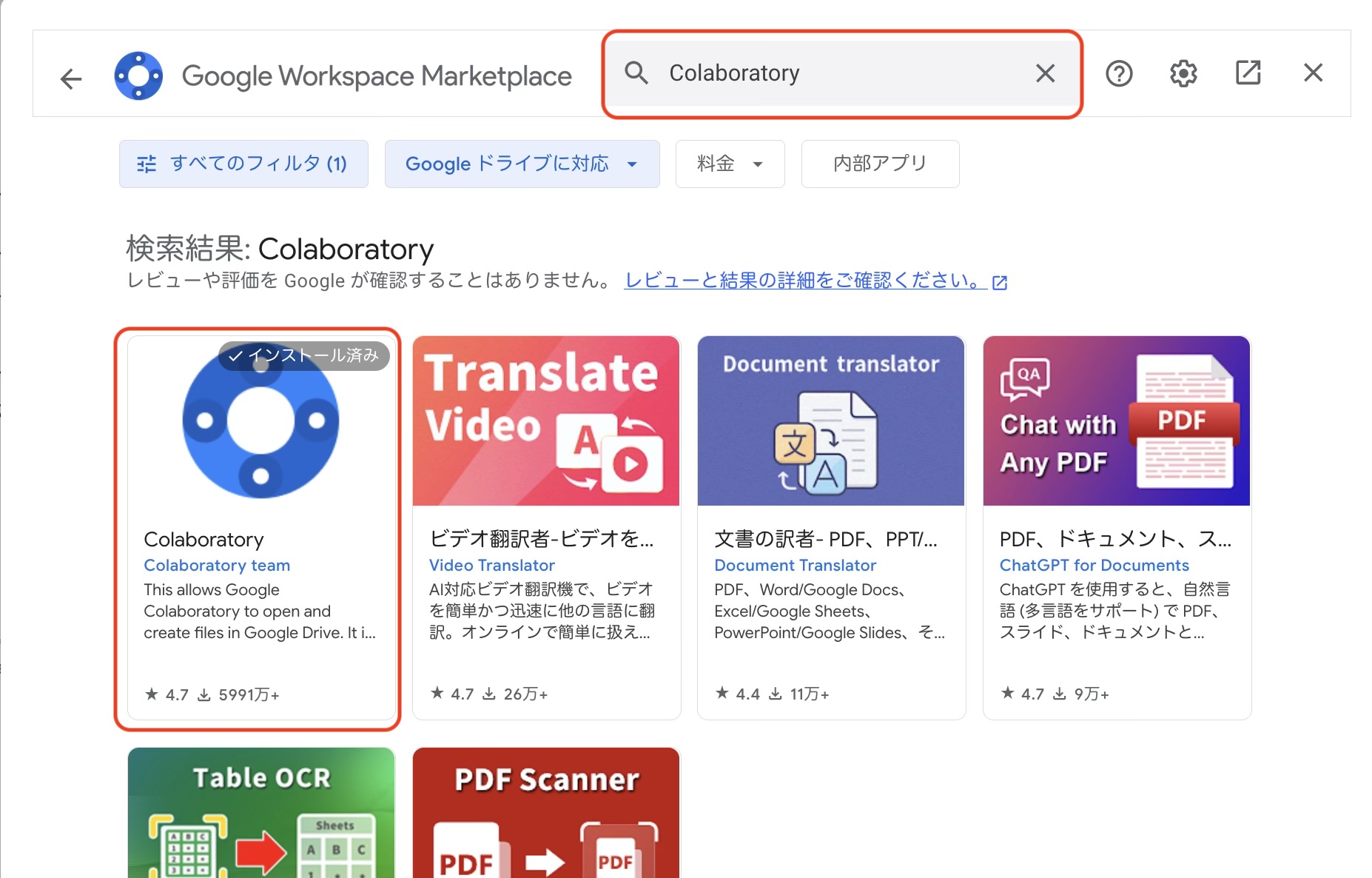
0.2.2 ノートブックの作成
google colabのファイルひとつひとつのことを「ノートブック (notebook)」とよぶ
新しいnotebookを作成する。
0.3 ここからnotebookの画面
これから表示するコードは「セル」に書いていく。
再生ボタン |> をクリックするとコードが実行される。
実行の仕方は、実行したい行を選択→Ctrl + Enter (Macでは⌘ + Enter) <- これ違うかも
Colabでは、結果を残したい計算はその都度セルに書いて実行するのが基本です。あとで見返したときに、どの順番で何を実行したかがそのまま残ります。
0.4 講義内課題1
ノートブックのセルに以下の内容を打ち込んでください。セル左のRunボタンを押すか、Ctrl + Enter (Macの場合は⌘ + Enter)で実行してください。
1 Pythonの基礎
Pythonの基礎
パッケージ
データの読み込み
データの処理
参考情報
課題
以後の例では、数値の並びや表形式データを扱うためにNumPyとpandasを使います。最初のセルで読み込んでおくと便利です。
1.1 計算
簡単な計算は、以下の通り
1.2 オブジェクト
Pythonでも情報を自分で名前をつけたオブジェクト (変数とも呼ぶ) として保存できます。
「=」の左はオブジェクト名、右はその中身を表します。なので、「xという名前のオブジェクトに3を入れる」という指示をしています。中身を確認するには、そのオブジェクト名(今回の場合z)をそのまま打てば大丈夫です。
一度オブジェクトを作っておけば、それを使った計算も可能です。
- 例えば、先ほど保存したzを使って、
文字列でもオブジェクトになります(その場合” “で囲みます)
これは数字じゃないので計算はできません
1.3 リスト
1.3.1 リスト
複数の数値の並びをまとめて扱うときは、リストを使うと便利です。
1.3.2 リスト
まずリストにデータを格納し、それをpd.DataFrameに変換する流れが基本です。
このリストをpd.DataFrameに変換すると、行名や列名をつけられて扱いやすくなります。
- 1
-
indexは行の名前、columnsは列の名前です。
| 列1 | 列2 | |
|---|---|---|
| 行1 | 435 | 165 |
| 行2 | 265 | 135 |
中に入っているものが全て数字なら、計算が可能です。
1.4 関数
Pythonでも関数は重要です。足し算引き算とかよりも高度な命令は関数やメソッドを使って行います。先ほど作ったベクトル(vec)を使って
Pythonでは、関数(対象)の形もあれば、対象.メソッド()の形もあります。今の例は前者です。
np.mean(vec)は、- 関数が
np.mean - 対象が
vec
1.5 データフレーム
オブジェクトの中で重要な形式として、データフレームがあります。これは、縦方向に観測値を、横方向に変数を並べたデータを言います。
- 1
- 年齢の列
- 2
- 性別の列
- 3
-
二つの列を
dframeという名前のデータフレームに
| age | gender | |
|---|---|---|
| 0 | 18 | female |
| 1 | 21 | male |
| 2 | 22 | male |
| 3 | 23 | female |
| 4 | 34 | female |
エクセル等のデータを読み込んで分析する場合は、このデータフレーム形式です。
データフレームの中の特定の列を指定する場合は、「データフレーム名["列名"]」と書きます。
データフレーム内の一部を取り出して関数を使って計算できます
1.6 講義内課題2
- 20点、35点、40点、70点、95点という5人の成績を示したテストの点数を表すベクトルを作成してください。オブジェクトの名前は
test_scoreとしてください。 - その平均点を求めてください
- (ヒント)
mean()に相当するメソッドを先に作成した点数の配列に対して使う。
- (ヒント)
- 学生の人数を収納する新たなオブジェクトを作成してください。名前は
Nとしてください。- (ヒント)
len()関数は配列の長さを返します。
- (ヒント)
1.7 パラメータと引数
パラメータ (parameters)、引数 (arguments) とは
関数の()の中に指定する値をパラメータと呼ぶ。例えば三つの引数を取る関数 example_function(A=2, B=10, C="ice")に関して、Aを第一パラメータ、Bを第二パラメータ、Cを第三パラメータと呼ぶ。パラメータに代入する値 (2, 10, “ice”) のことを引数という。 ただし、両方まとめて引数と呼んだりもする。関数ごとにパラメータの数や指定の仕方は異なる。
関数の中には(というかほとんどが)複数の引数を持ちます。
array([0.1 , 0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.2 ])np.arange()は連続した数を作る関数。- 一つ目の引数
start=0.1から、二つ目の引数stop=0.21の手前まで、三つ目の引数step=0.01ごとに数字を並べる
多くの関数は引数の定位置を持っていて、その順番に従った場合、上記のstartやstopといった指示は省略可能です。
array([0.1 , 0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.2 ])定位置以外の順番でやる場合は、指示が必要です。以下も同じです。
1.8 プログラムのスペースと改行
1.8.1 スペース
Pythonでも、半角スペースの入れ方で意味が変わらない場面は多いです。なので、以下は同じ結果になります。
でも、可読性のため、=の前後や2項演算子(+とか-とか)、あとコンマの後などには半角スペースを入れることが一般的です。
日本人がプログラムを打つときに失敗しがちなのが、記号やスペースを全角にすることです。代表的なものは全角カッコや全角コンマや全角スペースです。全角スペースはひらがなや漢字などと同じ文字として認識されるので、全角スペースを入れるとエラーになります。半角スペース二つと全角スペースは、ぱっと見見分けがつかないので注意!
1.8.2 改行
Pythonでも、()や[]の中では改行しても動作します。特に構造が深いときは、改行したほうが見やすいかもしれません。例えば、上でやった行列の作成コマンド
は、以下のように書いても全く同じように動作します。
あまり改行しすぎるのもかえって読みにくいかもしれません。自分が見やすいように程よく改行してください。
2 パッケージ
Pythonの基礎
パッケージ
データの読み込み
データの処理
参考情報
課題
より高度なことをしたり、同じことをより簡単にしたりするために追加の機能を足すことができます。
この追加の機能をパッケージといいます。
Python本体がスマートフォンのOSのようなもので、パッケージはアプリのようなもの。


2.1 パッケージのインストールと利用
2.1.1 インストール
Pythonでは、必要なパッケージを最初にインストールしてから使います。ColabにはNumPyやpandasが最初から入っていることが多いですが、入っていない環境では以下のようにします。
Colabでは、ノートブックの先頭セルにこのようなインストール用コードを書くのが一般的です。
2.1.2 利用
パッケージを使う時には、分析ファイルを実行する最初の段階で以下のコマンドを使います(スマートフォンにすでに入っているアプリを開くイメージ)。
3 データの読み込み
Pythonの基礎
パッケージ
データの読み込み
データの処理
参考情報
課題
さっきはデータを下記のように手打ちしました。
しかし、アンケートデータや、企業の会計データ等をこのように手打ちするのは現実的ではありません。エクセル等で集計されたデータを読み込むのが一般的です。
- 例えばgoogle formsでアンケートを作成したら、googleスプレットシート(googleのエクセルみたいなもの)に自動的に集計されます。
以下では、エクセルファイルを読み込む方法についてまとめています。
3.1 準備
- 講義ウェブサイトの上のバーからDataに進み、第2回の「2_tests」データをダウンロード
- Colabの左側にある「Files」から
dataフォルダを作り、その中に2_tests.csvをアップロードしてください
3.2 前提
エクセルで列が変数、行が観測となるようにデータを作られていることを想定します。まず、これを表計算ソフト上でcsv形式で保存します1。この講義では、Colab上のdataフォルダに置いた想定で進めます。
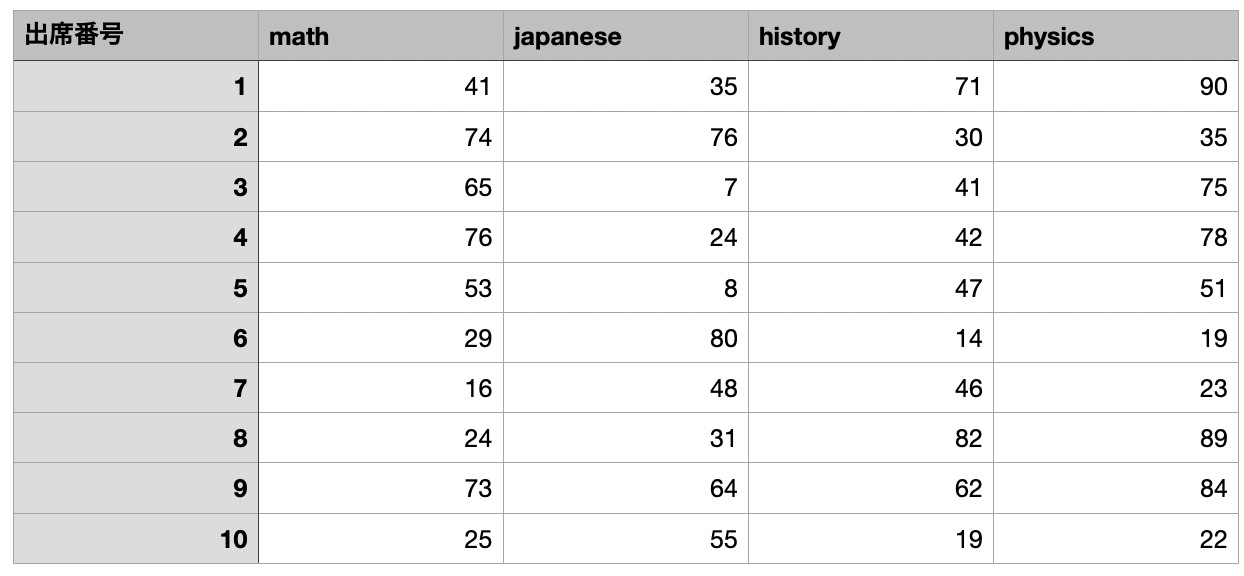
3.2.1 csvファイルの取り込み
dataフォルダに入れたファイルを読み込むには、pd.read_csv("ファイル名")を使います1。ここでは、2_tests.csvと言う名前のデータを、testsと言う名前で読み込んでいます。
読み込んだデータを見てみます。最初のいくつかだけが表示されるhead()メソッドが便利です。
4 データの処理
Pythonの基礎
パッケージ
データの読み込み
データの処理
参考情報
課題
4.1 新しい変数の作成
現在のデータにはない、4教科の合計点が欲しいとします。Pythonでは、新しい列を代入する形で作ることが多いです。今回は元のデータに付け足す形で作ります。
testsの各列を使って作った新しい変数を、all列として追加しています。
5 参考情報
Pythonの基礎
パッケージ
データの読み込み
データの処理
参考情報
課題
5.1 エラーについて
プログラミングをやってて一番むかつき、嫌いになる要因はエラーメッセージ
- いわゆるバグがある状態
できることは
- エラーメッセージをちゃんと読むこと
- エラーメッセージをそのままググること
「エラーが出てたら99.99%自分が悪い(パソコンは悪くない)」ということを自覚すること

5.2 Python標準機能とpandas
Pythonにも分析に必要なさまざまな機能が装備されています。
しかし、
- 同じことをもっとわかりやすく書ける機能
- 新しい分析手法の開発に合わせた新しい関数
などは、パッケージとして提供されます。
- Pythonでは、表形式データを扱うときに
pandas、数値計算にNumPyを使うことが多いです。
この講義でも、表の処理はpandas、配列の計算はNumPyを中心に進めます。
標準のPythonだけでも書けることは多いですが、データ分析ではこの2つを使うほうがずっと実用的です.
6 課題
Pythonの基礎
パッケージ
データの読み込み
データの処理
参考情報
課題
この回の内容を復習するための課題です。
6.1 手順
- Google Drive の「吉田ゼミ」フォルダに新しい Colab ノートブックを作成する
- ノートブック名を 「task01」 に変更する(ファイル名をクリックすると編集できます)
- 以下の3問を解くコードを書いてセルを実行する
- 「共有」ボタンからURLを取得して提出する
ノートブックの最初のセルに import numpy as np と import pandas as pd を書いて実行してから始めてください。
6.2 問1: 変数と計算
身長 170 cm、体重 65 kg の人のBMIを計算してください。それぞれ変数 height、weight として保存してから計算してください。
\[\text{BMI} = \frac{\text{体重 (kg)}}{\text{身長 (m)}^2}\]
(ヒント: 身長の単位に注意してください)
6.3 問2: リストと統計
以下は10人の1週間の読書時間(時間)です。
- このリストを
readingという名前で保存してください - 平均・最大・最小の読書時間を計算してください
6.4 問3: データフレームの作成
以下のデータをデータフレーム members として作成し、年齢(age列)の平均を計算してください。
| name | age | hometown |
|---|---|---|
| Aさん | 18 | 大阪 |
| Bさん | 20 | 東京 |
| Cさん | 19 | 名古屋 |
| Dさん | 21 | 福岡 |
ゼミ