4 データの可視化
2026/04/30
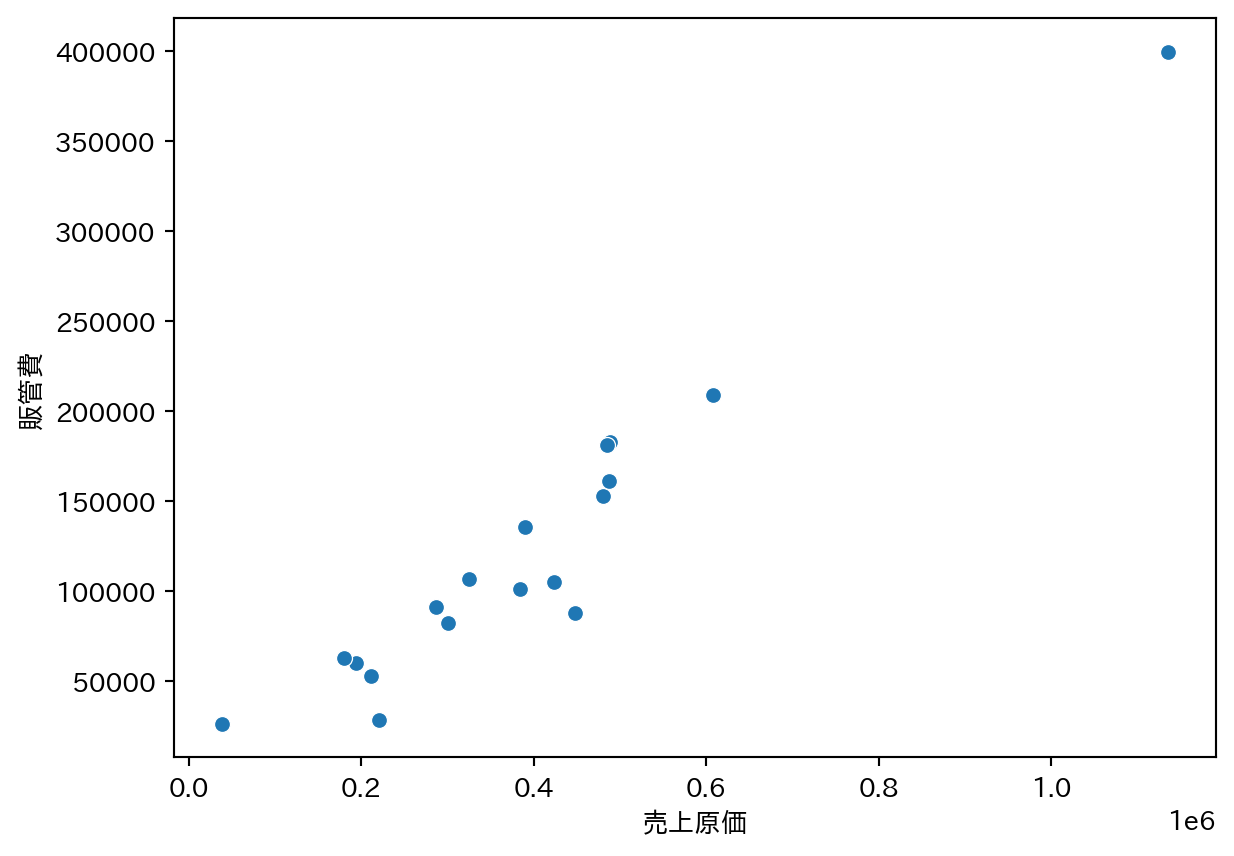
3 散布図
2つの変数の関係を視覚的に確認するための第一歩。統計的な分析に進む前に、まずグラフで全体像をつかむことが重要。
4 回帰直線付き散布図
散布図に回帰直線を重ねると、相関の強さと方向を直感的に把握できる。lmplot が自動で直線を描いてくれる。
大きな数字が指数表示(例:2e+05)になってしまう場合は ticklabel_format で通常の数字表示に切り替える。
(array([-200000., 0., 200000., 400000., 600000., 800000.,
1000000., 1200000., 1400000., 1600000., 1800000.]),
[Text(-200000.0, 0, '−200000'),
Text(0.0, 0, '0'),
Text(200000.0, 0, '200000'),
Text(400000.0, 0, '400000'),
Text(600000.0, 0, '600000'),
Text(800000.0, 0, '800000'),
Text(1000000.0, 0, '1000000'),
Text(1200000.0, 0, '1200000'),
Text(1400000.0, 0, '1400000'),
Text(1600000.0, 0, '1600000'),
Text(1800000.0, 0, '1800000')])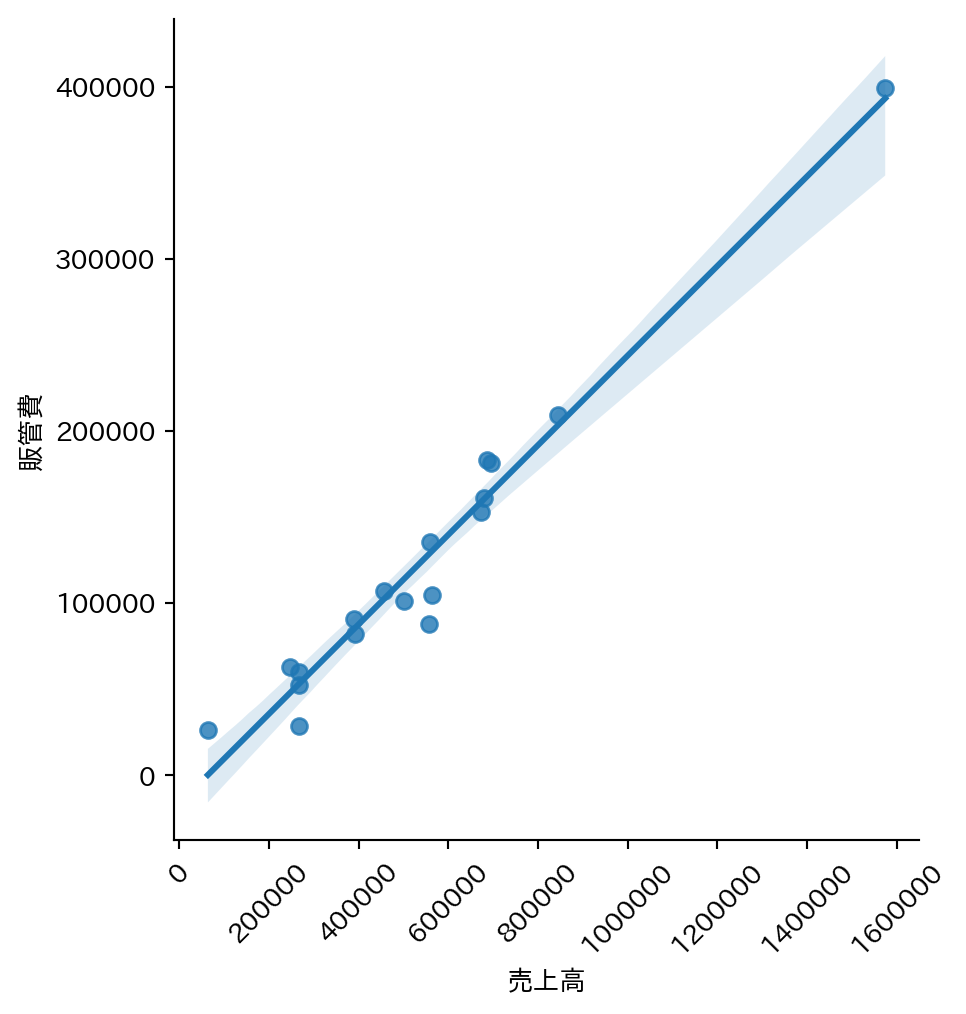
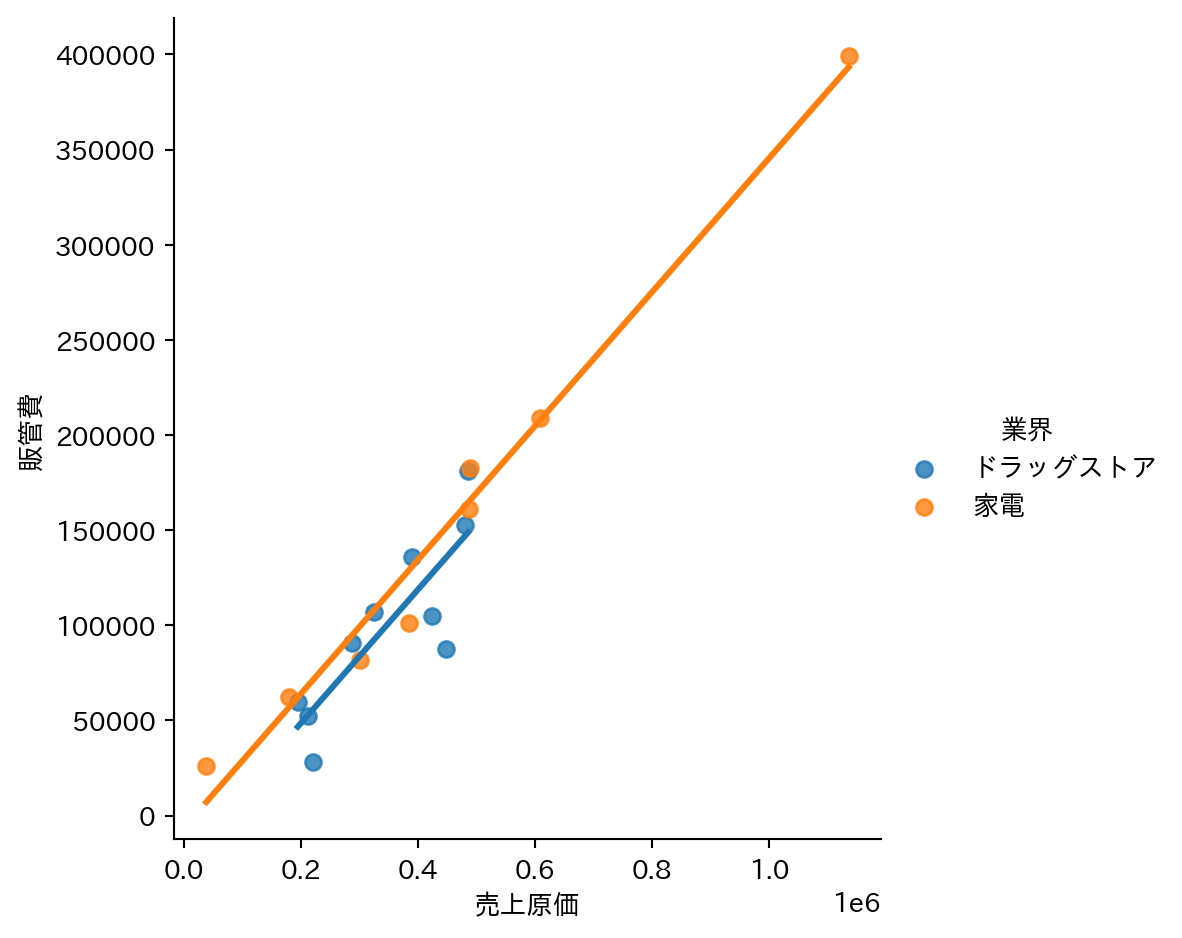
4.1 業界別の回帰直線
hue でグループを色分けすることで、業界ごとのパターンの違いが見えてくる。全体でひとつの直線を引くだけでは見落としていた業界間の差を確認できる。
5 ヒストグラム
変数の分布の形状(正規分布か、右寄り・左寄りの偏りがあるかなど)を確認する。multiple="dodge" でグループを横に並べて比較しやすくする。
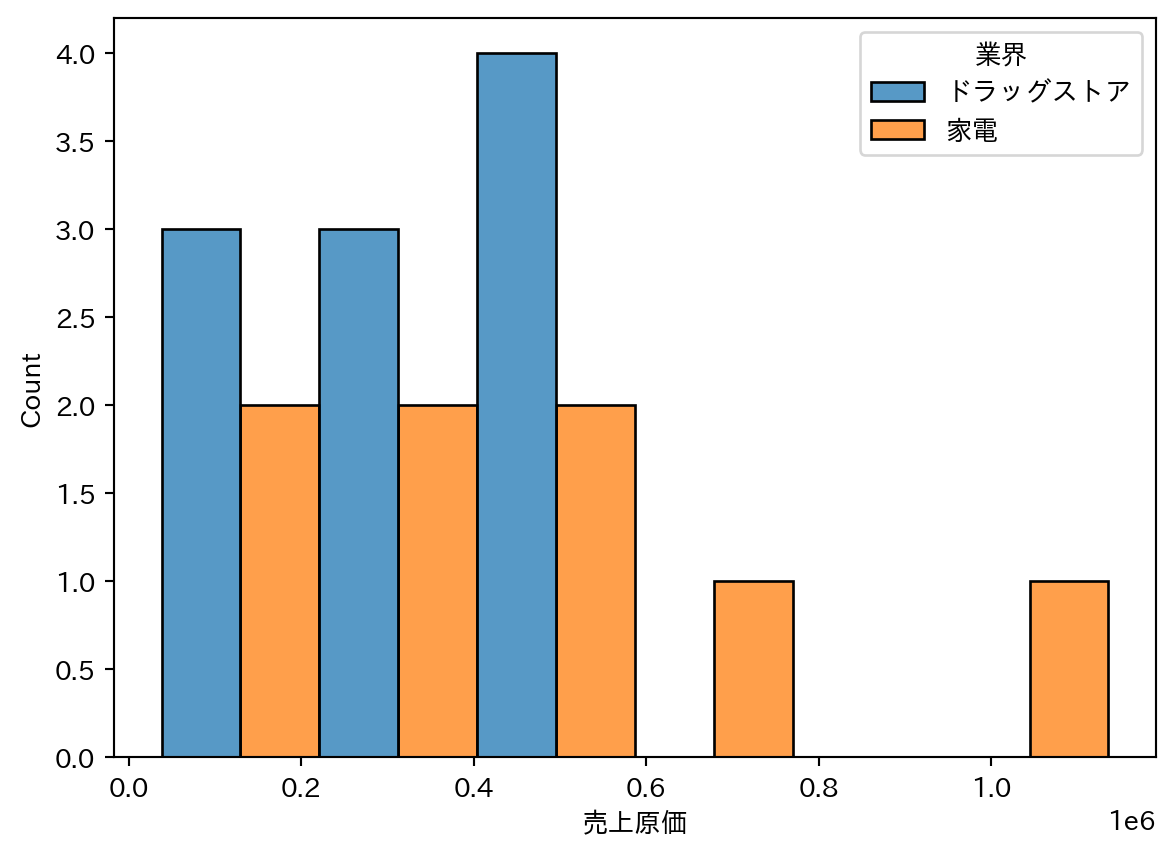
6 バイオリンプロット
箱ひげ図と密度分布を組み合わせたグラフ。グループ間の分布の違い(中央値・ばらつき・形状)を一度に比較できる。
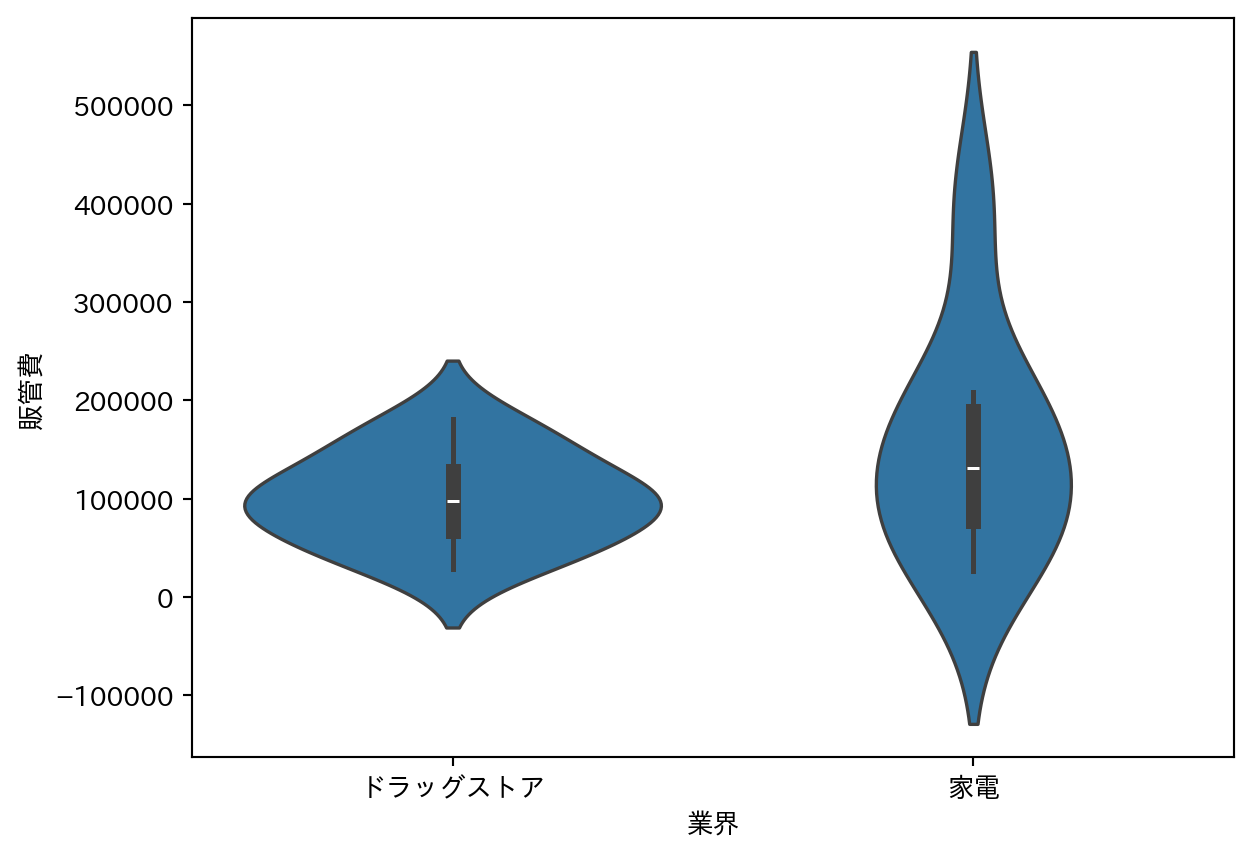
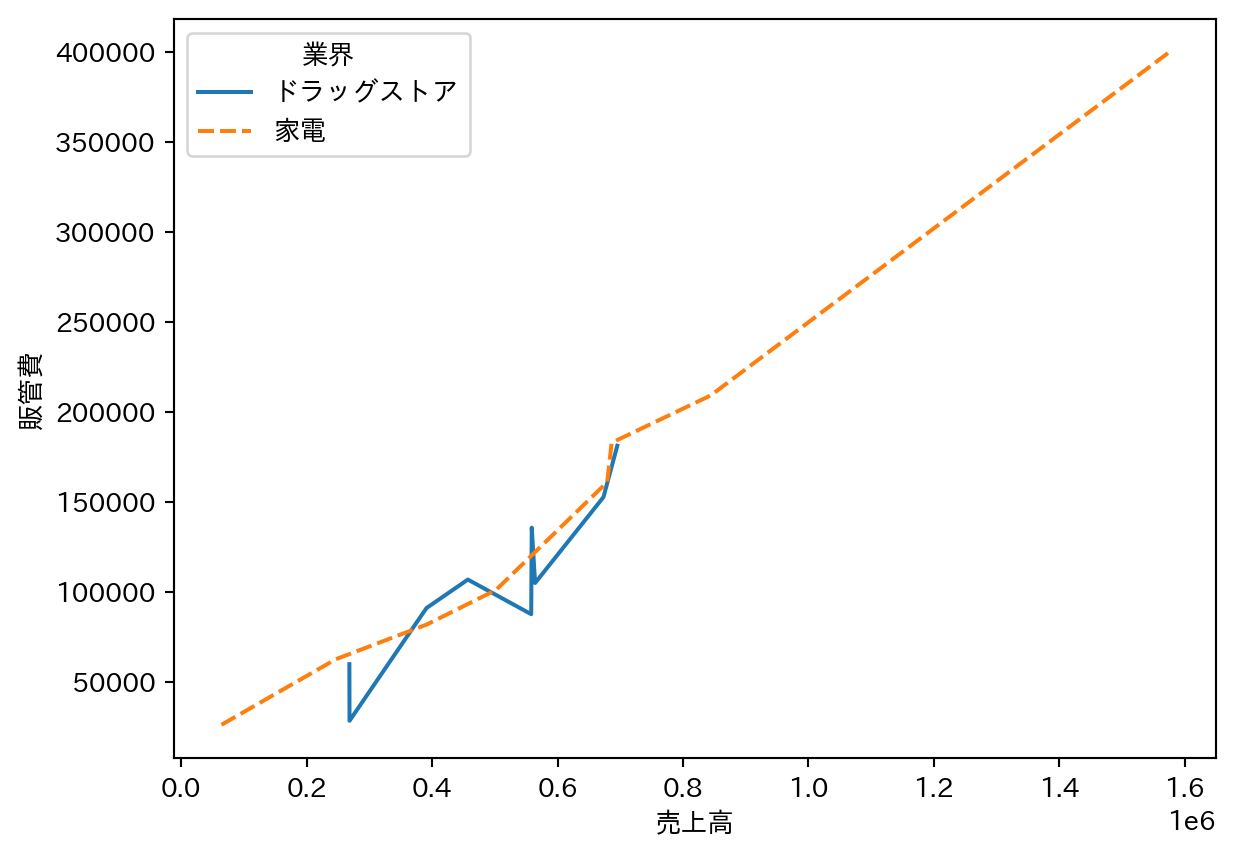
7 折れ線グラフ
変数の連続的な変化やトレンドを表すのに適している。hue と style を組み合わせると、グループを色と線の種類の両方で区別できる。