6 回帰分析
2026/05/07
1 導入と準備
導入と準備
回帰分析
結果の解釈
1.1 2変数間の関係性を知りたい
基本的には片方が原因でもう片方が結果だと考える
- ex. 業績連動給を導入すると努力量は増えるのか
- 変数1: 業績連動給
- 変数2: 努力量
- ex. ESGに積極的な企業の業績は高いのか
- 変数1: ESGへの積極性
- 変数2: 企業業績
- ex. 在庫の多く抱える会社の原価は高いのか
- 変数1: 在庫の量
- 変数2: 売上原価
1.2 必要なパッケージを読み込む
1.3 データを準備する
今回から、業種データが結合済みのデータを使います
| 銘柄コード | 会社名 | 売上高 | 売上原価 | 販管費 | 総資産 | 負債 | 純資産 | 売上債権 | 棚卸資産 | 仕入債務 | 法人税等 | 業界 | 営業利益 | roa | 売上高利益率 | 総資産回転率 | 従業員数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2664 | カワチ薬品 | 268205 | 211068 | 52563 | 183303 | 32019 | 91880 | 3073 | 29846 | 38390 | 1918 | ドラッグストア | 4574 | 0.024953 | 0.017054 | 1.463178 | 2598 |
| 1 | 2730 | エディオン | 686284 | 488119 | 182786 | 369547 | 65930 | 169005 | 34530 | 111703 | 47130 | 4579 | 家電 | 15379 | 0.041616 | 0.022409 | 1.857095 | 8653 |
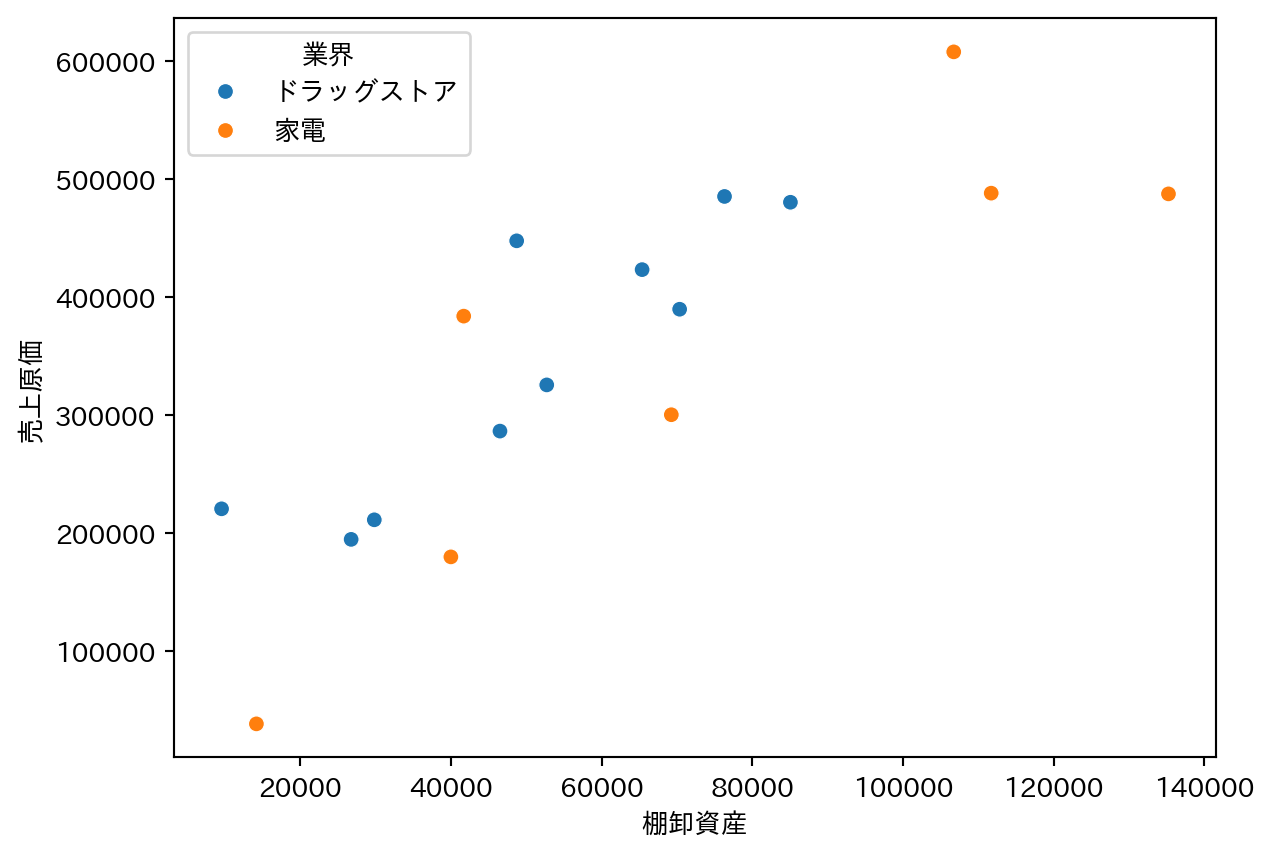
1.4 散布図で関係を確認する
回帰分析を実行する前に、まず散布図で変数間の関係を目で確認する。外れ値の有無や非線形な関係がないかをチェックするためのステップ。
2 回帰分析
導入と準備
回帰分析
結果の解釈
2.1 2変数間の関係性は直線で表すのが一番簡単
直線の公式:\(y = \alpha + \beta x + \varepsilon\)
- yが結果の変数で、xが原因の変数を表す
- \(\beta > 0\): 右肩上がり
- \(\beta = 0\): 水平
- \(\beta < 0\): 右肩下がり
2.2 データから直線を推定する
直線の式が分かればxとyの関係性が(ある程度)わかる。
直線の式 (特に、\(\beta\)) が知りたい。
データに最もフィットする \(\beta\) を推定したい。
→ 最小二乗法
2.3 回帰分析(OLS)
最小二乗法(OLS: Ordinary Least Squares)で回帰直線を推定する。 データと直線の誤差が最小になるように直線の式を推定する。
ex. 「棚卸資産が1単位増えたとき、売上原価がどれだけ変わるか」という関係を数値で表す。
smf.ols("目的変数 ~ 説明変数", data=df) という形で式を書く。
2.3.1 結果の読み方
| 項目 | 見る場所 | 意味 |
|---|---|---|
| 係数 | 棚卸資産 の行の coef |
棚卸資産が1増えると売上原価がこの数値だけ変わる |
| 信頼区間 | [0.025 0.975] |
0をまたいでいるのかどうか。またいでいなければ5%水準で統計的に有意という |
| p値 | P>|t| |
信頼区間の結果を一つの数値で示したもの。0.05より小さければ5%水準で有意という |
2.4 業界別の回帰分析
全業界を一緒に分析するより、同業界内で比較するほうが異質性をコントロールできる。業界によって事業モデルが違うため、業界を固定すると係数の解釈がより明確になる。
| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 130514.212725 | 43192.507293 | 3.021686 | 0.016517 | 30912.112296 | 230116.313153 |
| 棚卸資産 | 4.222349 | 0.771979 | 5.469512 | 0.000595 | 2.442162 | 6.002536 |
| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 89280.496883 | 56783.432665 | 1.572298 | 0.166942 | -49663.557455 | 228224.551220 |
| 棚卸資産 | 3.561273 | 0.430915 | 8.264434 | 0.000170 | 2.506860 | 4.615685 |
全体と業界別で係数や決定係数がどう変わるか比較してみよう。
3 結果の解釈
導入と準備
回帰分析
結果の解釈
3.1 係数 \(\beta\) の見方
\(\beta\) がプラス、マイナス、ゼロかだけで結論を急いではいけない
Important
コインを100回投げると何回表が出るだろうか?50回? その予想は妥当であり、これを期待値という(計算の方法は省略)。 では、実際に100回投げると50回となるだろうか。ぴったり50回になるとは限らない。 つまり、一番起こりやすいとしてもピンポイントでそうなることは少ない。 係数の推定でも同じである。本当の効果が0.05であってもぴったり0.05となる確率は小さい。反対に、本当の効果が0 (効果なし) であったとしても、ぴったり0と推定されるとは限らない。
だから幅で評価してあげる必要がある。
- 幅が0に重なっていなければ(端から端までプラス or 端から端までマイナス)なら0ではないといえる。
- この状態を「n%水準で有意である」という
- 重なっていれば0の可能性を否定できない。
上記からわかるように、有意でない場合、0の可能性を否定できないと同時に、影響している可能性も残されている。
そのため、有意でないときは「影響がないとはいえない」という解釈をする。決して「影響がない」とは言わない。
母集団と推定と検定とp値と信頼区間について謎の長文
母集団とは母なる大地である。 そこは真実の地である。 広大な土地が広がっているらしいが誰も見たことがない。 そこから土のサンプルを持ち帰ることに成功した。 その地質を調査をすれば、どんな微生物がいる、てことはこんな虫がいて、それを食べる動物がいて、と母なる大地のことを類推することができる。こんな気候だ、こんな匂いがする、と。
サンプルが少なければ母なる大地の可能性は広く、人によって異なる可能性を提示してくる。
もっと多くのサンプルが集まったらどうだろうか。 色々な提示されていた可能性からあり得ないもの、否定されるものが出てきて、母なる大地の可能性が狭まってくる。 これが推定という行為である。 サンプルを集めて、そのサンプルに対して分析をして、母集団のことを類推する。 サンプルが多くなったり、分析手法が適切になると、母集団のことをより正確に・詳細に知ることができる。
この考え方を応用して検定という行為をする。 AとBの平均値は異なっている(大きい)だろうか。Aは基準値と異なっている(大きい)だろうか。ということを調べられる。 これを帰無仮説とよび、具体的には「Aの平均値とBの平均値は同じである」、「Aは0(基準値)と同じである」というふうに〜と同じという形をする。
母集団には真実があるため、Aの母集団における平均値とBの母集団における平均値が異なっていればこの帰無仮説は間違いということになる。同じであれば正しいことになる。しかし、我々は母集団のことを完全に知ることはできない。こんな感じかなと類推するだけである。そのため、Aの母集団での平均値の可能性には幅があり、Bについても幅がある。サンプルを使って比較する場合、平均値だけではなくその幅も考慮して比較しないといけない。
かなりジャンプして説明すると、どれくらい可能性を狭めるかを考えるのが信頼区間である。 信頼区間100%であれば、何回サンプル抽出を繰り返してもその幅の中に母集団の値が100%含まれている。無限の幅を持たせれば、幅のどこかに正解があるだろうということである。 幅を狭めていけばその幅の中に母集団の値が含まれている可能性が小さくなる。 ちなみに、信頼区間95%とは、正確には「同じ方法で標本抽出を無限回繰り返したとき、作られる区間の95%が真値を含む」ことであり、95%の確率で母集団の値が入っている区間ではない。
Aと基準値を比べるときを考える。Aの幅に基準値が含まれないなら、母集団におけるAの値も基準値ではない可能性が高いといえる。基準値が0でAの幅に0が含まれないなら(例えば、Aが1 ~ 5 という幅をもつなら)、Aは0ではないでしょうとなる。これが回帰分析の係数で行っていることである。つまり、Aがβである。βが0と異なるのかどうかを調べている。
Aと0を比べることは比較対象2つの差(AとBの差)と0を比べていることに置き換えられる。素直にAとBを比較するよりAとBの差を0と比較する方が都合が良い。次の同値が成り立つから(AとBの幅の重なりと有意は同値ではない)。
「信頼区間95%でAとBの差が0を含まないこと」と「有意水準5%で有意なこと」は同値である。この有意性を表す指標がp値で、定義は、帰無仮説が真だと仮定した時に現在の検定統計量以上の値が得られる確率である。p値が基準値(ex. 5%)より小さい時、信頼区間(ex. 95%)が0と重なっていない。
一方で、完全に違うとは言い切れない。同じではないという言い方をする。あくまで帰無仮説の「〜同じ」であることを否定しただけだからである。
もし差の幅に0が含まれる時、両者は違う可能性もあるが、同じ可能性も残る。つまり、なんともいえない。 ここからわかるように、同じであることを主張するのは非常に難しい。 違いについてはかなり強くいえるが、反対は「違うかもしれないし同じかもしれない」くらいである。つまり、違うことを否定はしていない。
3.2 係数プロット
幅で評価する方法が信頼区間、係数プロットあたりである。
- 係数の情報を抜き出す
- プロットする
以下のコードを一つのセルに書く
# おまじない
fig, ax = plt.subplots(figsize=(6, 3))
# 点:推定値
sns.scatterplot(
x=coef_df["Coef."],
y=coef_df.index,
zorder=3,
ax=ax
)
# 線:95% 信頼区間
ax.hlines(
y=coef_df.index,
xmin=coef_df["[0.025"],
xmax=coef_df["0.975]"]
)
# ゼロ線
ax.axvline(
0,
color="gray",
linestyle="--",
linewidth=0.8
)
ax.set_xlabel("Estimate (95% CI)")Text(0.5, 0, 'Estimate (95% CI)')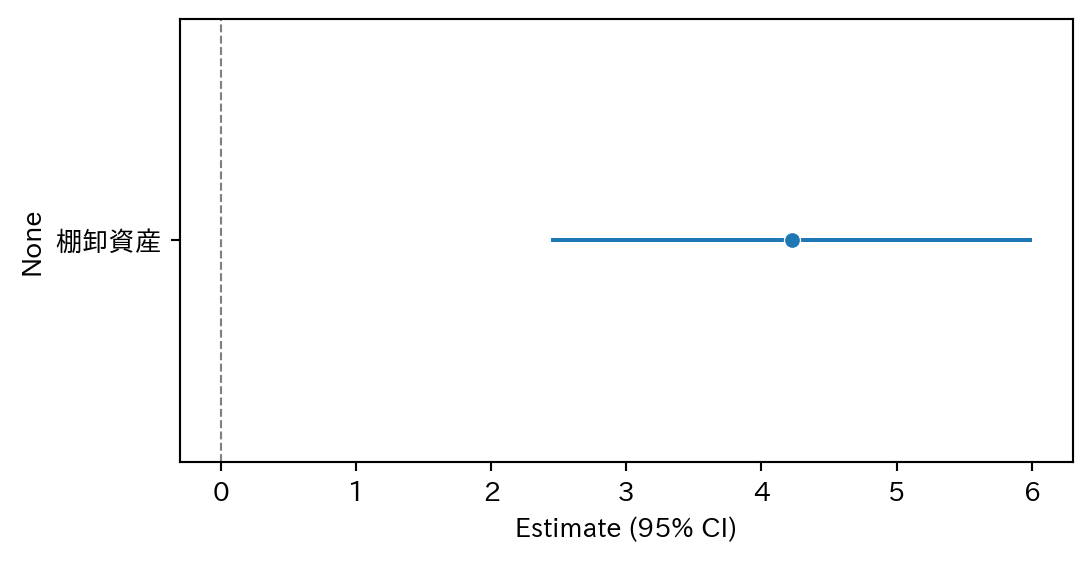
横線が0にかかっていなければ、信頼区間に0を含まないし、5%水準で有意 (p値が0.05未満) であることを意味する
3.3 あらためて母集団と推定
- サンプリングされたデータで計算された数字(ex.平均値)は母集団の数字とぴったり一致するとは限らない
- サンプリングされたデータで計算された数字から母集団の数字を推測する
- でもピンポイントでは当てれないから幅のある推測をする
- サンプルサイズが大きければ、母集団の数字と大きくは外れていないだろうから、予測幅が狭まる
- サンプルサイズが小さければ、母集団の数字と大きくは外れる可能性が大きくて、予測幅が大きくなる
3.4 有意と検定
実は係数の信頼区間やp値というのは検定というのをした結果を表しています。ここでは、係数が0と異なるのか(大きいのか・小さいのか)を検定しています。
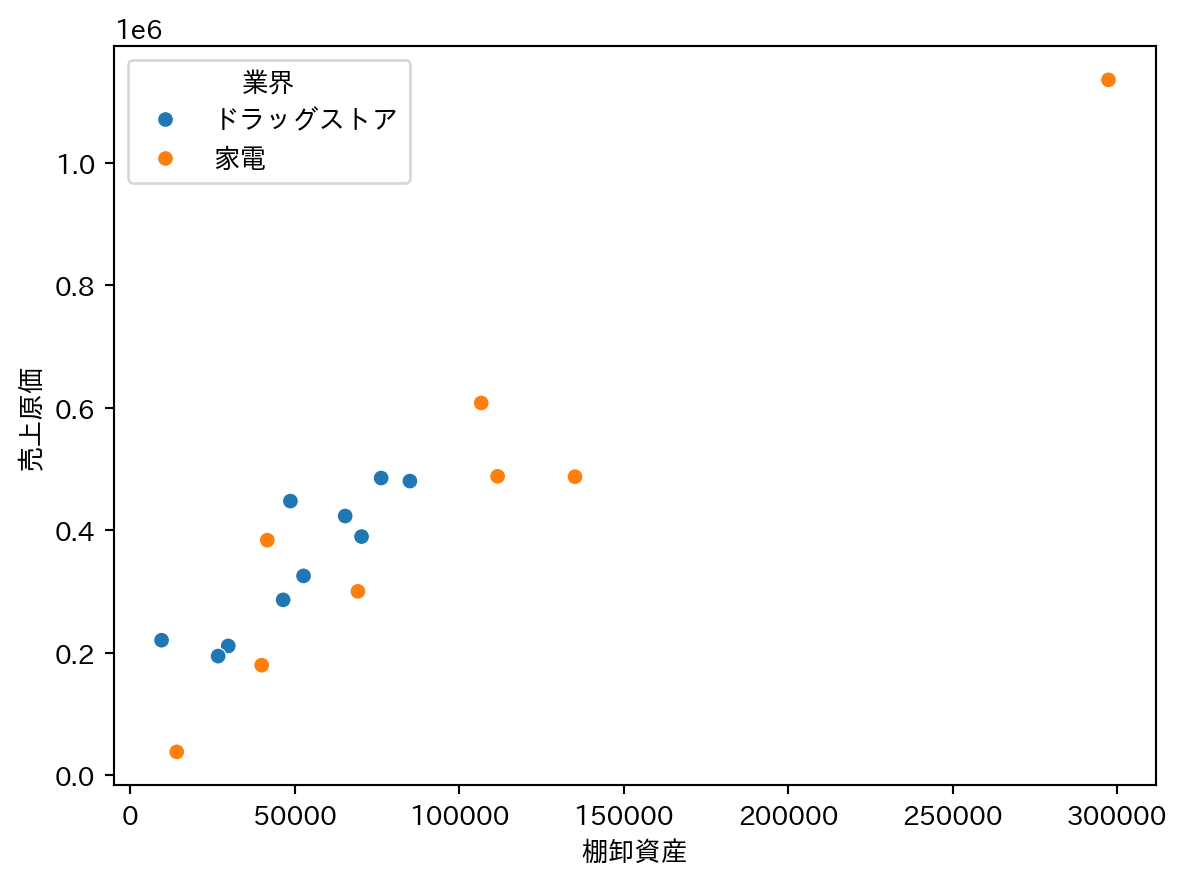
3.5 外れ値を除去する
外れ値(飛び抜けて大きな値)があると、そこに引っ張られて回帰直線が大きく歪んでしまう。99パーセンタイルを超える値を上限として除去することで、外れ値の影響を取り除くという方法もある。
まず99パーセンタイルの値を確認する。
確認した閾値を使って外れ値を除去する。