8 研究デザインと出版用テーブル
2026/05/21
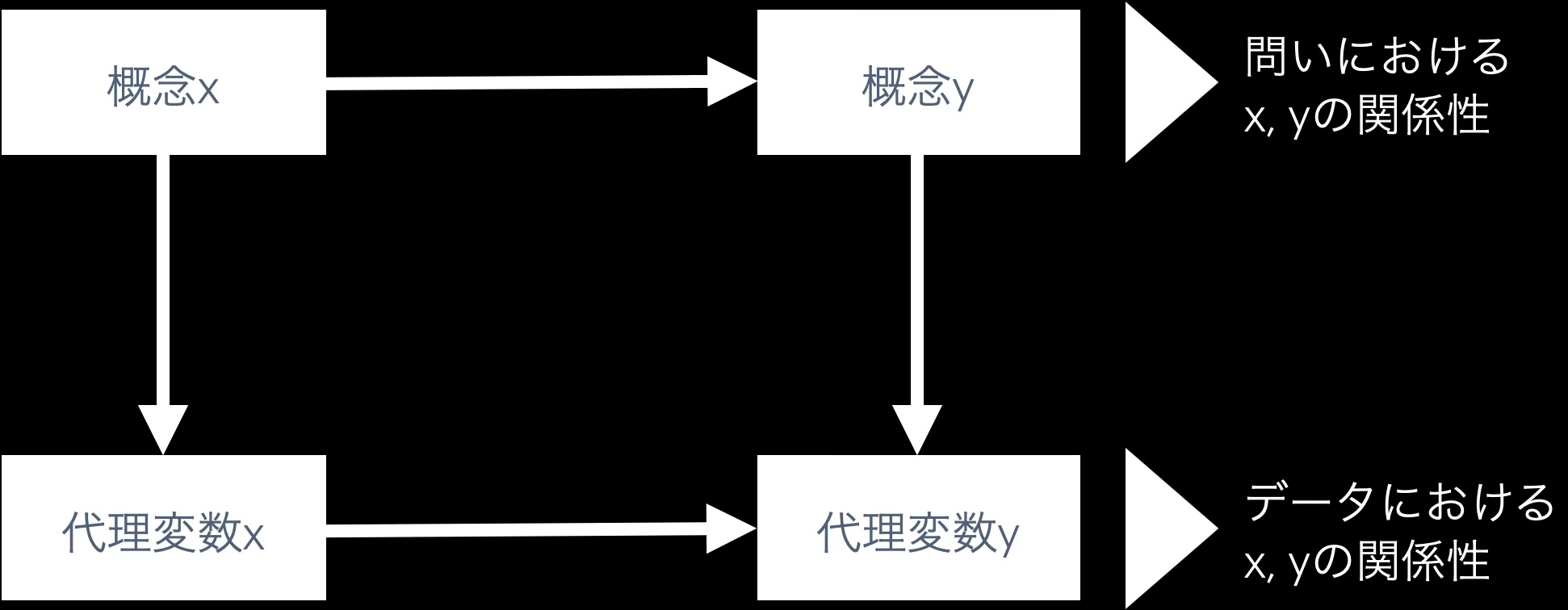
- 4つの箱を使って概念と代理変数を整理する
- 代理変数が概念を妥当に代理できているのか視覚的にわかりやすい
- データの関係性だけ取り出した時に関係性が変になっていないかとかも考えられる
1.2.1 経営学にありそうな例
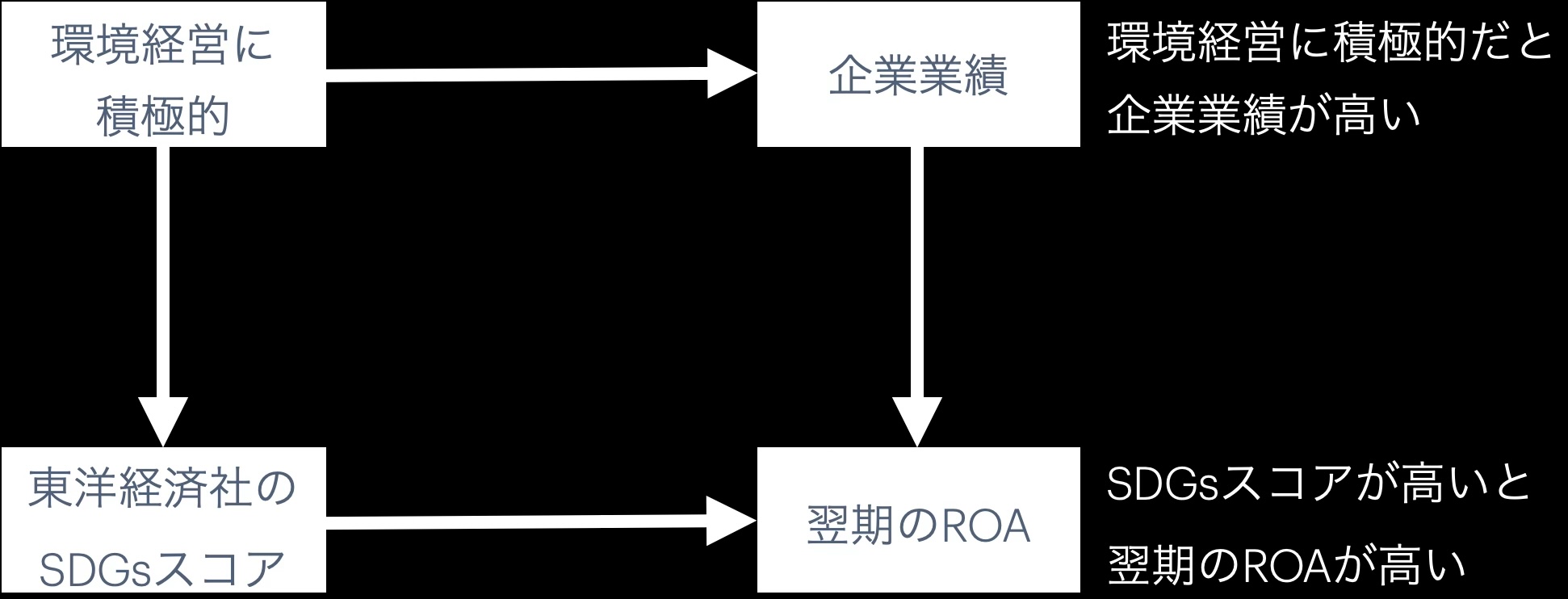
- それぞれの代理変数としての妥当性を考えつつ
- スコアとROAは同じ年で良いのか、1年後か、もっと後か
- みたいにデータだけの関係性で考えることができる
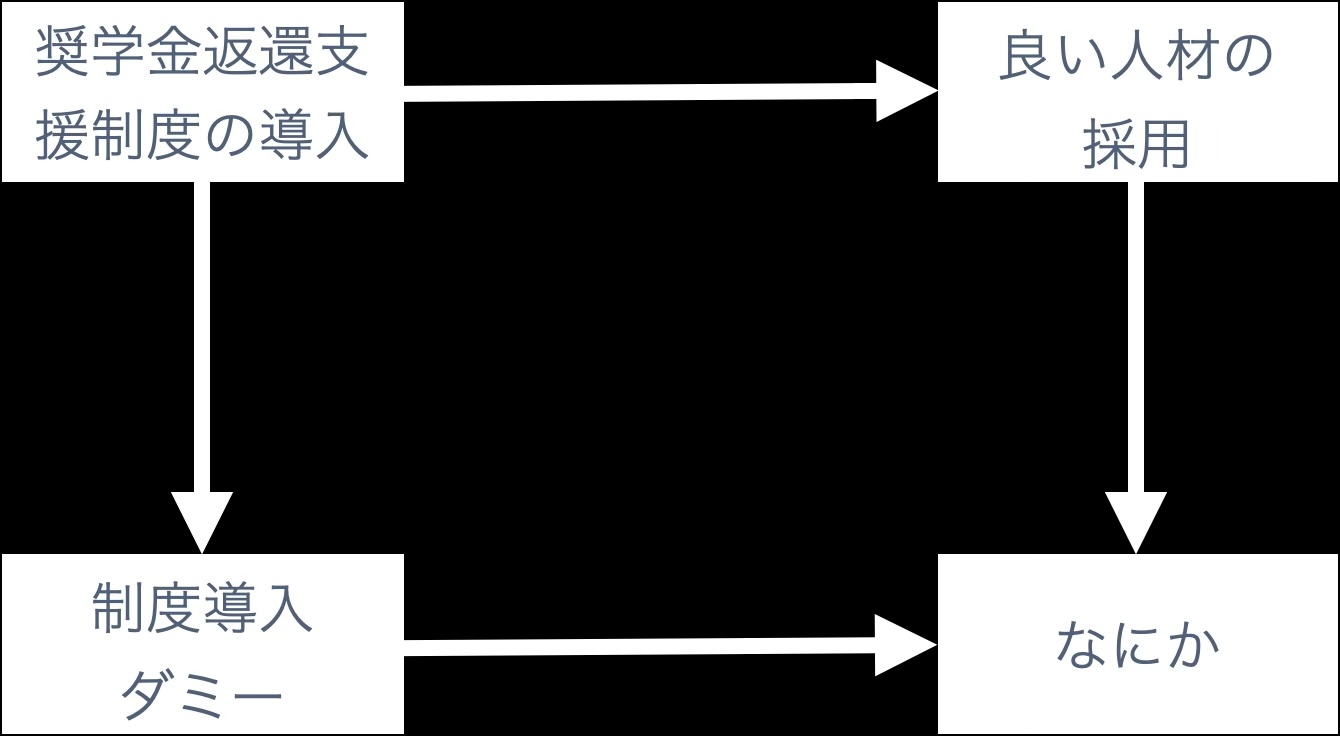
1.2.2 よくある代理変数:ダミー変数
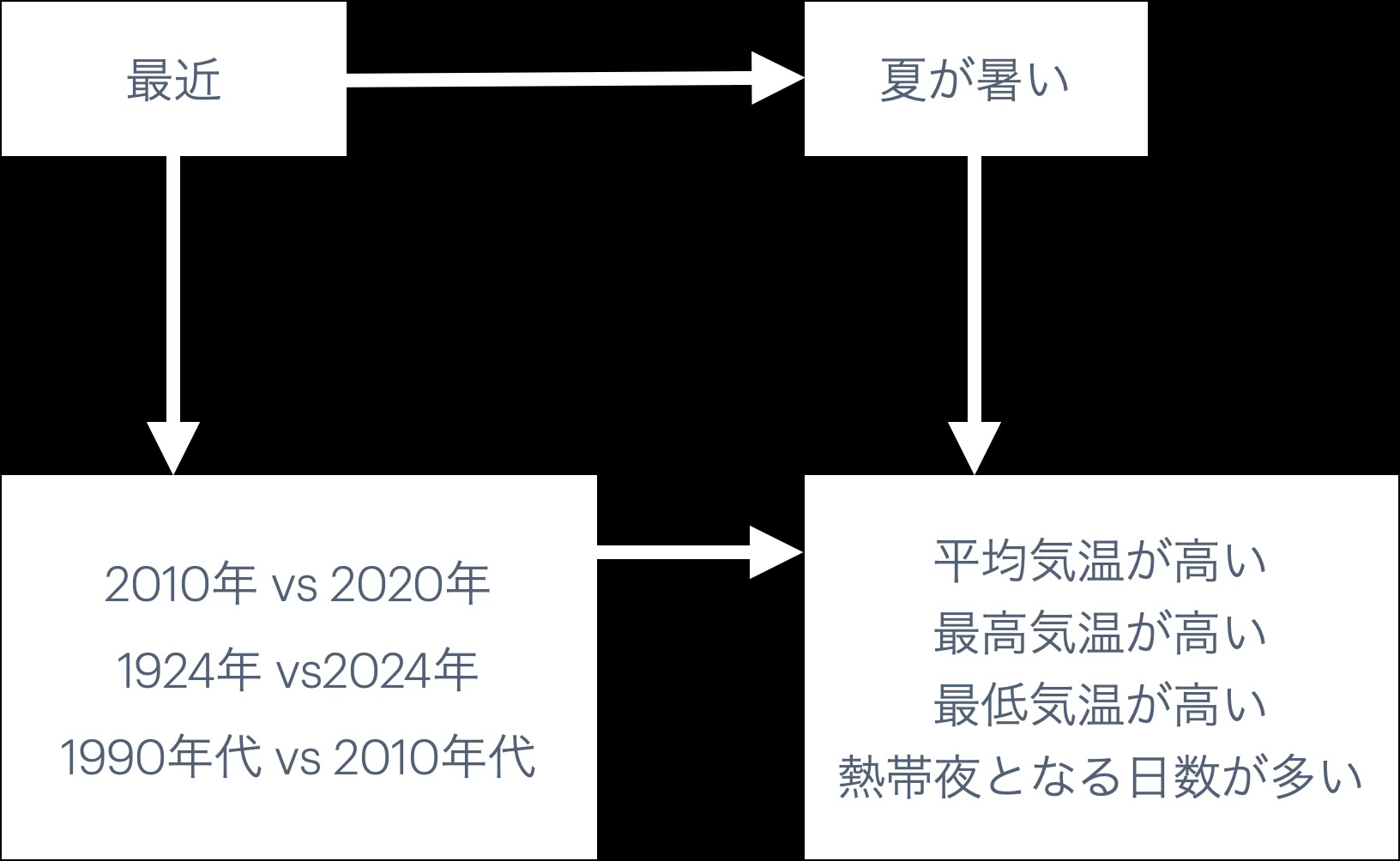
1.2.3 夏は暑い、再び
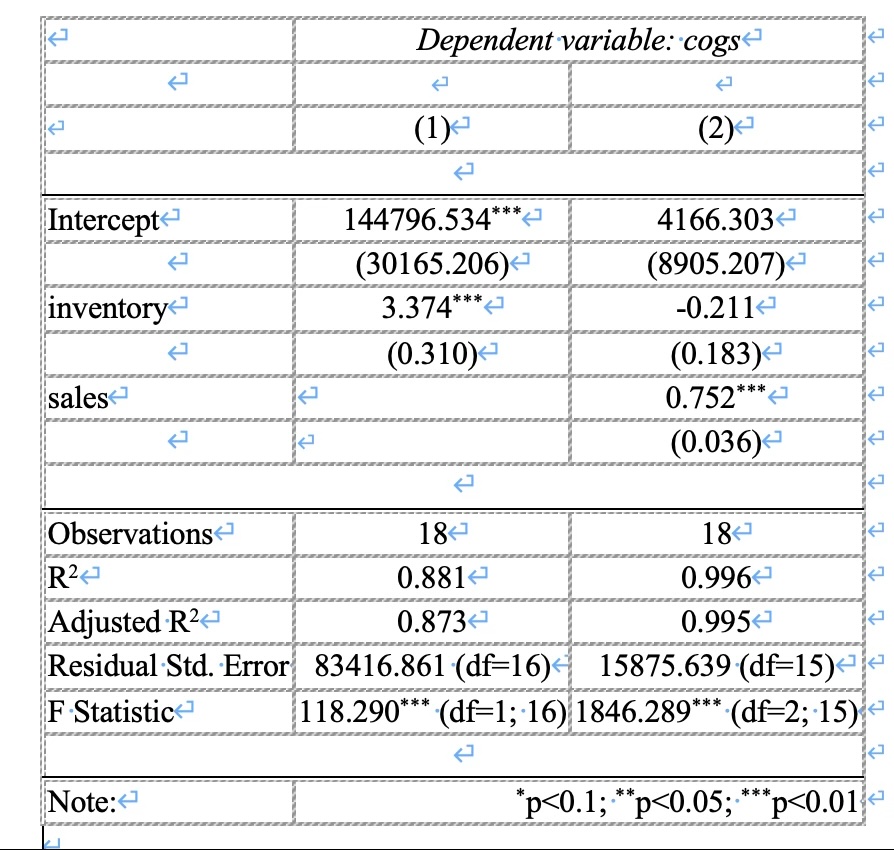
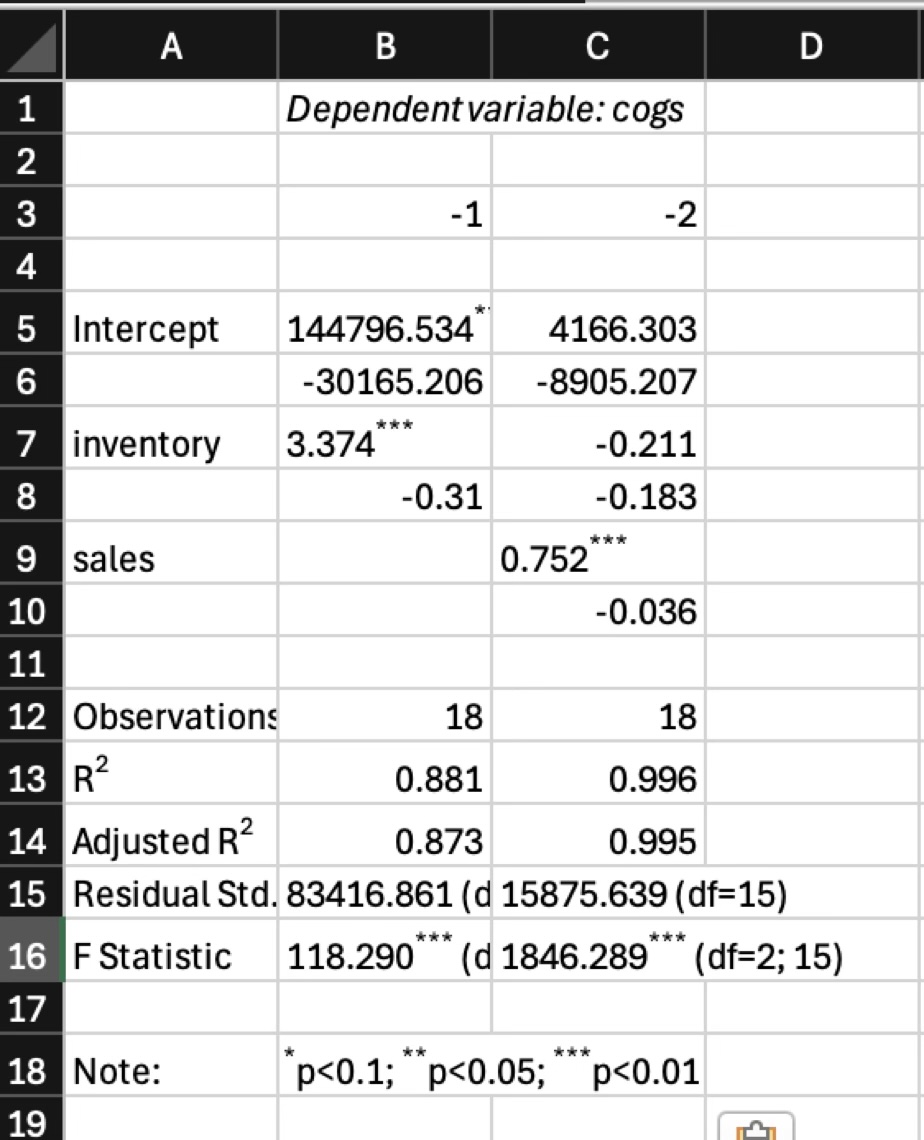
2.1 Publication Ready Table(stargazer)
学術論文では複数のモデルを横に並べた係数表を掲載するのが慣習。モデル(1)は基本モデル、モデル(2)以降でコントロール変数を追加するという構成が多い。
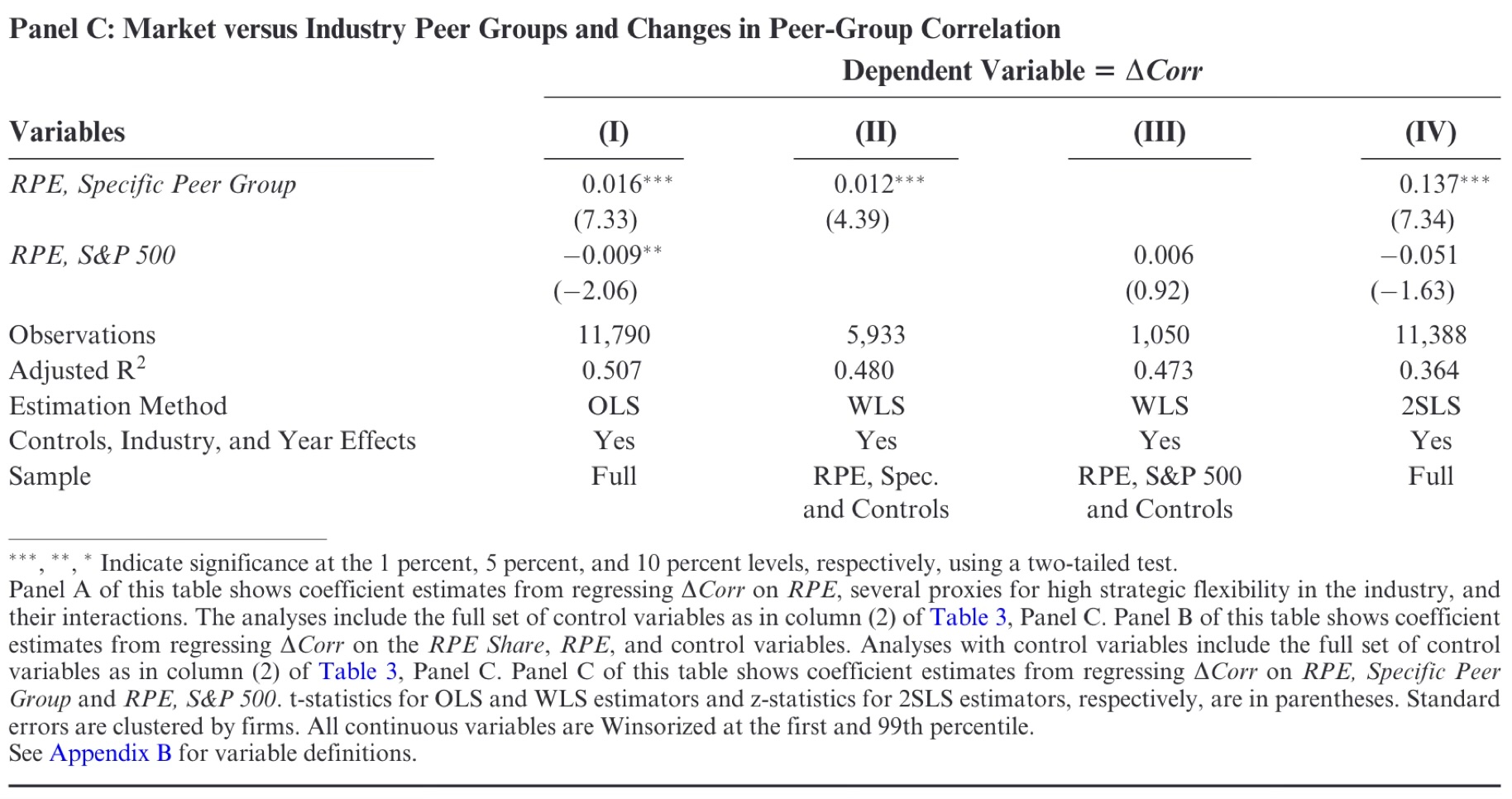
卒論では、このアウトプットをwordとかexcelに貼り付けるだけで8割型完成する。
値を手打ちするよりミスが少ない!!