Code
!pip install japanize-matplotlib可視化には seaborn と matplotlib を使う。
また、グラフに日本語を表示するために japanize-matplotlib が必要(Colabでは毎回インストールが必要)。
!pip install japanize-matplotlibパッケージの読み込み (japanize_matplotlibを読み込むときは、さっきと-と_が違うので注意)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
import scipy前回と同じ手順で財務データと業界データを読み込み・結合し、ROAを計算する。
df_fin = pd.read_csv(
"drive/MyDrive/自分で作ったフォルダの名前/findata.csv",
encoding="cp932"
)
df_ind = pd.read_csv(
"drive/MyDrive/自分で作ったフォルダの名前/inddata.csv",
encoding="cp932"
)# 2つのデータを結合する
df_fin_ind = pd.merge(df_fin, df_ind, on=["銘柄コード", "会社名"])
df_fin_ind["営業利益"] = df_fin_ind["売上高"] - df_fin_ind["売上原価"] - df_fin_ind["販管費"]
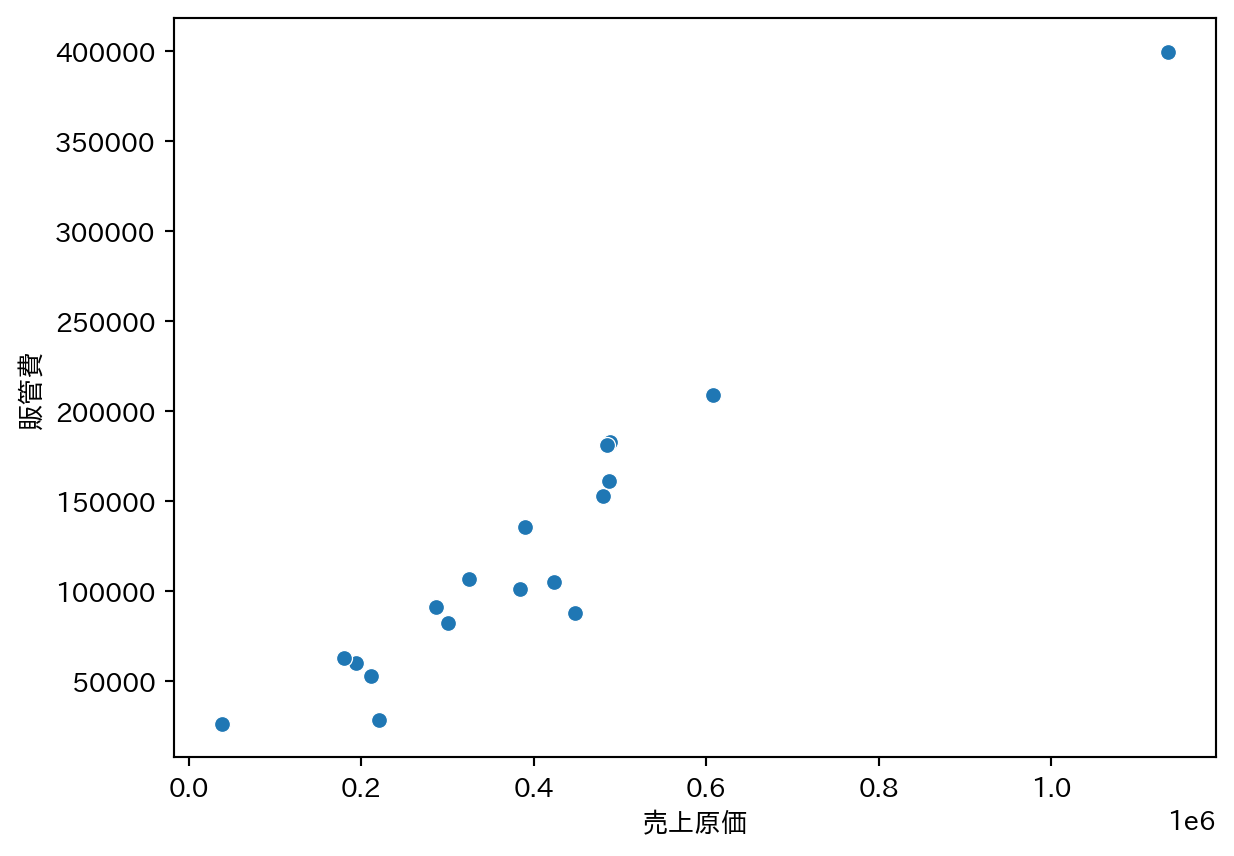
df_fin_ind["roa"] = df_fin_ind["営業利益"] / df_fin_ind["総資産"]2つの変数の関係を視覚的に確認するための第一歩。統計的な分析に進む前に、まずグラフで全体像をつかむことが重要。
sns.scatterplot(
data=df_fin_ind,
x="売上原価",
y="販管費"
)
散布図に回帰直線を重ねると、相関の強さと方向を直感的に把握できる。lmplot が自動で直線を描いてくれる。
大きな数字が指数表示(例:2e+05)になってしまう場合は ticklabel_format で通常の数字表示に切り替える。
軸を回転させたほうが見やすいこともある。
g = sns.lmplot(
data=df_fin_ind,
x="売上高",
y="販管費"
)
for ax in g.axes.flat:
ax.ticklabel_format(style="plain", axis="x")
plt.xticks(rotation=45)(array([-200000., 0., 200000., 400000., 600000., 800000.,
1000000., 1200000., 1400000., 1600000., 1800000.]),
[Text(-200000.0, 0, '−200000'),
Text(0.0, 0, '0'),
Text(200000.0, 0, '200000'),
Text(400000.0, 0, '400000'),
Text(600000.0, 0, '600000'),
Text(800000.0, 0, '800000'),
Text(1000000.0, 0, '1000000'),
Text(1200000.0, 0, '1200000'),
Text(1400000.0, 0, '1400000'),
Text(1600000.0, 0, '1600000'),
Text(1800000.0, 0, '1800000')])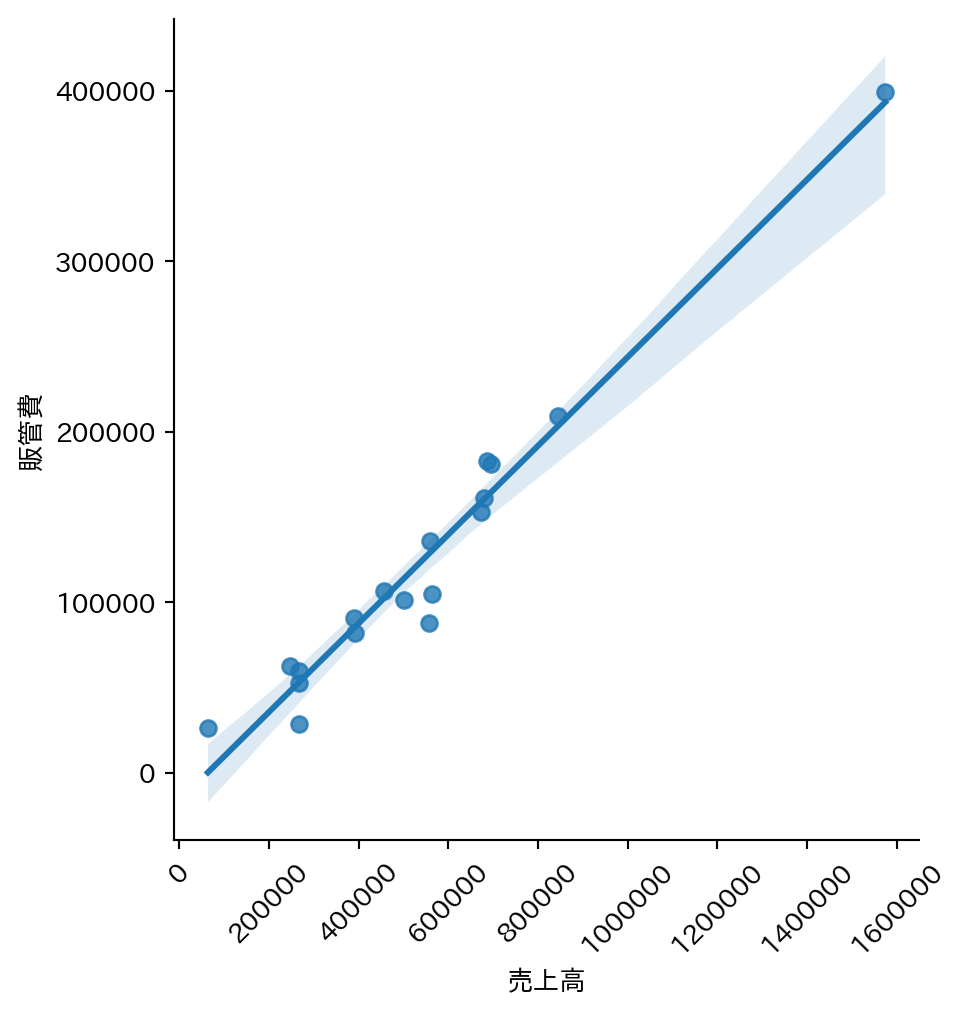
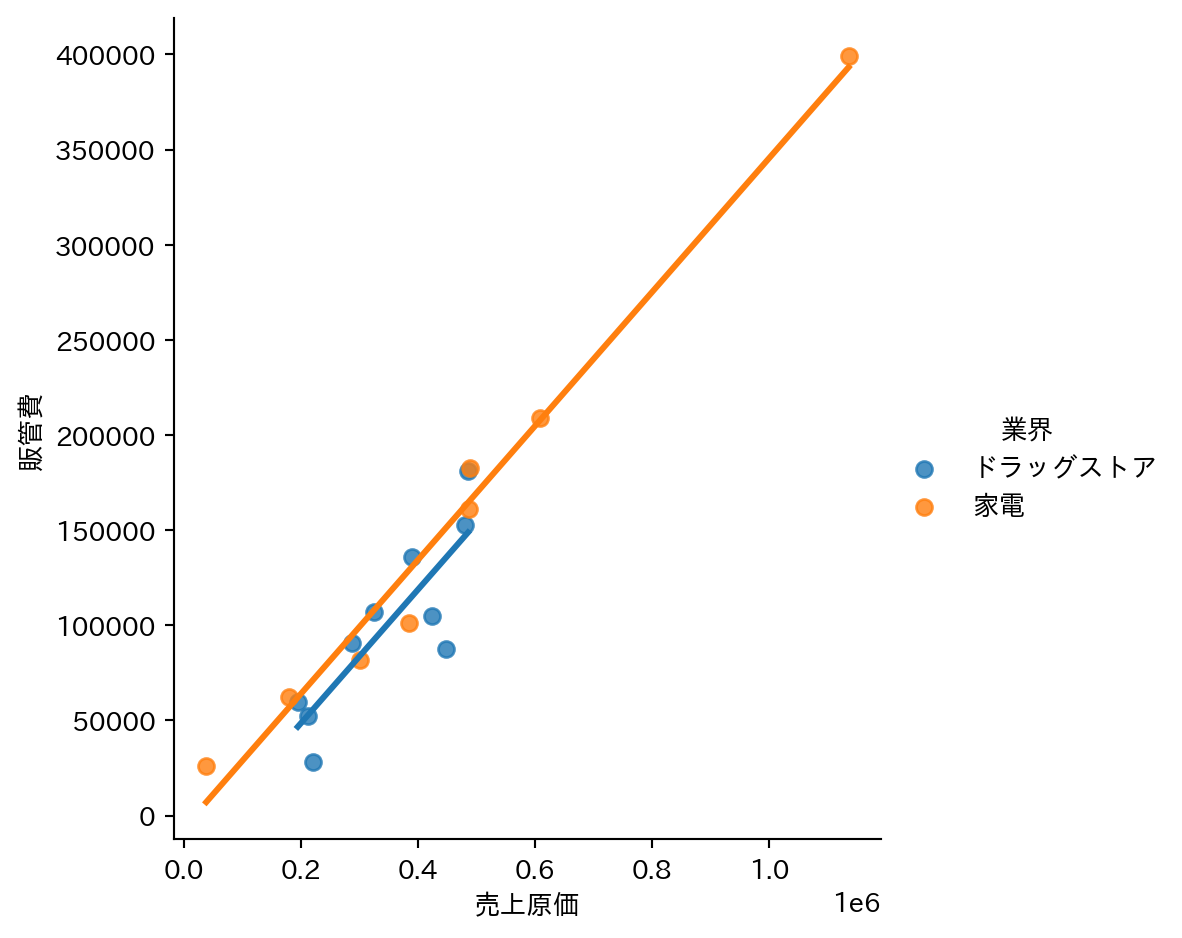
hue でグループを色分けすることで、業界ごとのパターンの違いが見えてくる。全体でひとつの直線を引くだけでは見落としていた業界間の差を確認できる。
sns.lmplot(
data=df_fin_ind,
x="売上原価",
y="販管費",
hue="業界",
ci=None
)
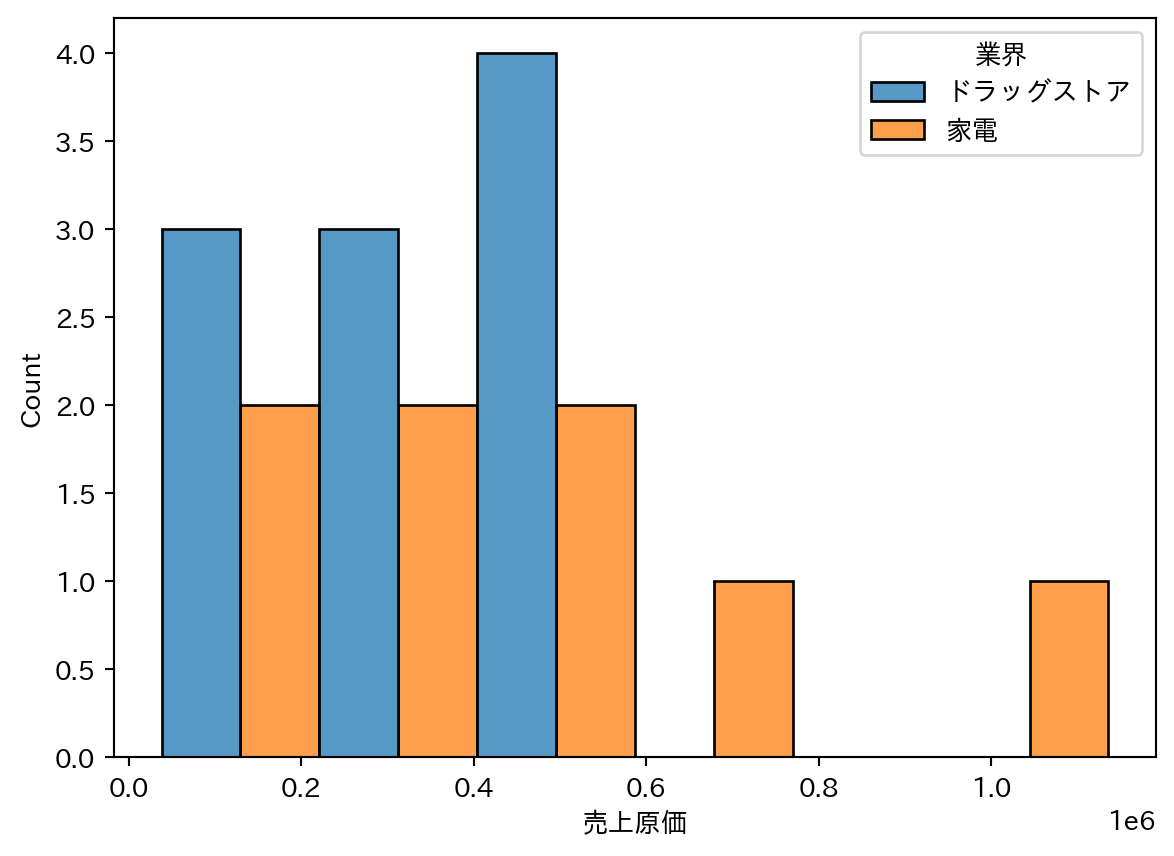
変数の分布の形状(正規分布か、右寄り・左寄りの偏りがあるかなど)を確認する。multiple="dodge" でグループを横に並べて比較しやすくする。
sns.histplot(
data=df_fin_ind,
x="売上原価",
hue="業界",
multiple="dodge"
)
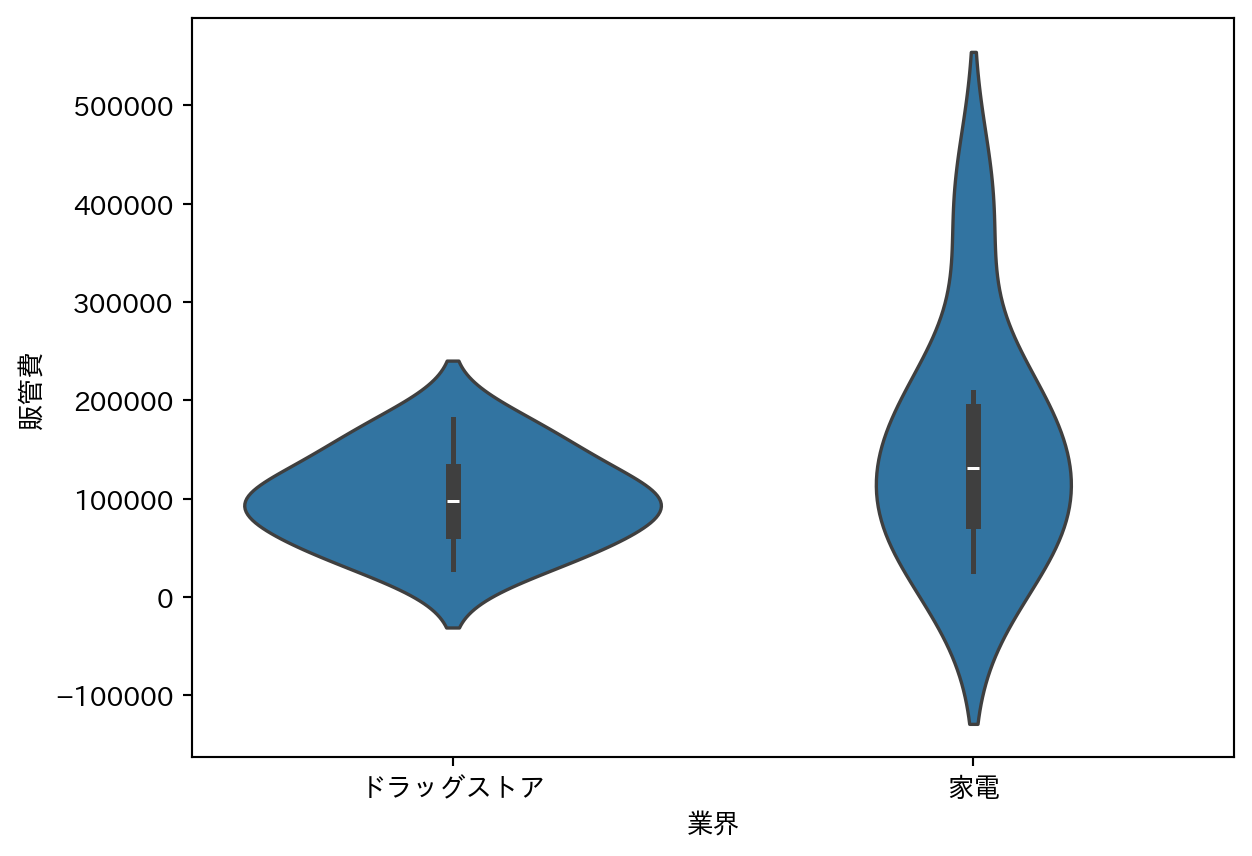
箱ひげ図と密度分布を組み合わせたグラフ。グループ間の分布の違い(中央値・ばらつき・形状)を一度に比較できる。
sns.violinplot(
data=df_fin_ind,
x="業界",
y="販管費"
)
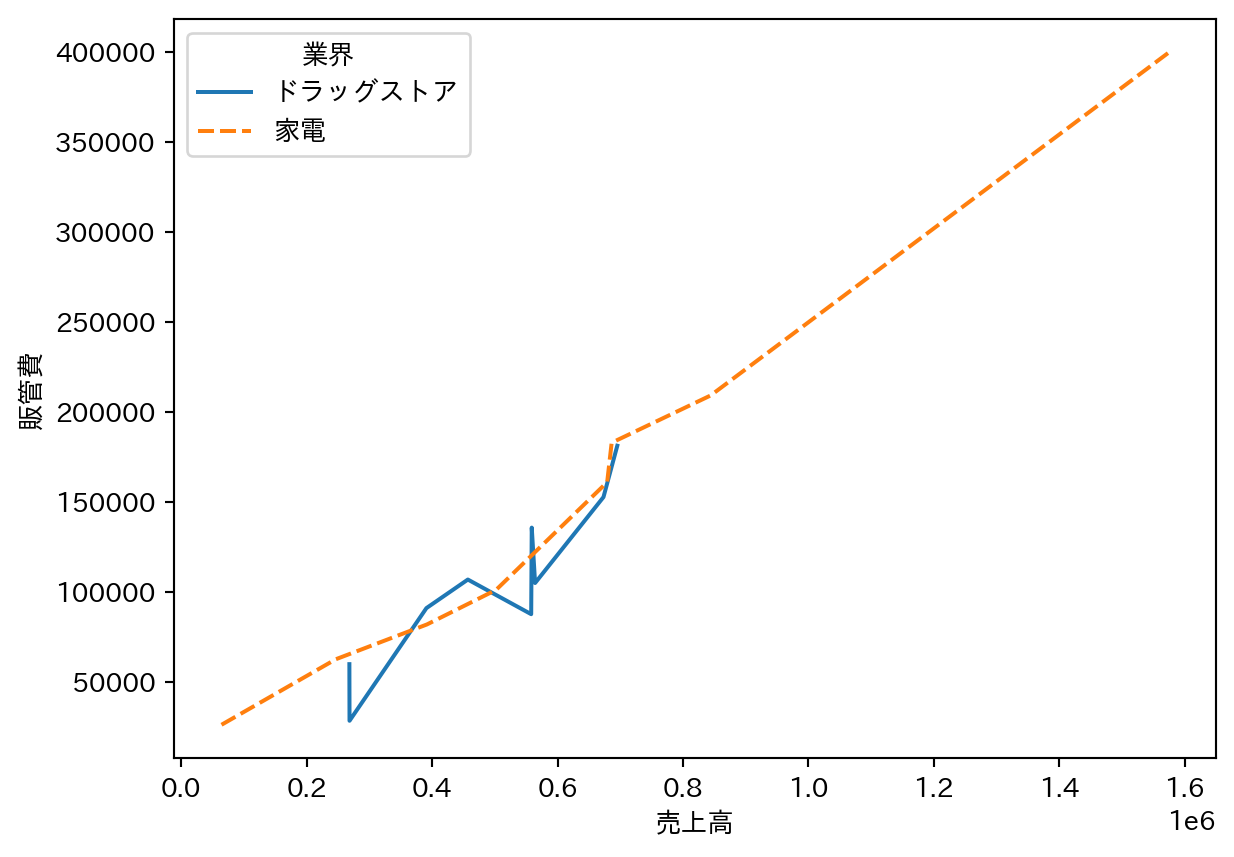
変数の連続的な変化やトレンドを表すのに適している。hue と style を組み合わせると、グループを色と線の種類の両方で区別できる。
sns.lineplot(
data=df_fin_ind,
x="売上高",
y="販管費",
hue="業界",
style="業界"
)
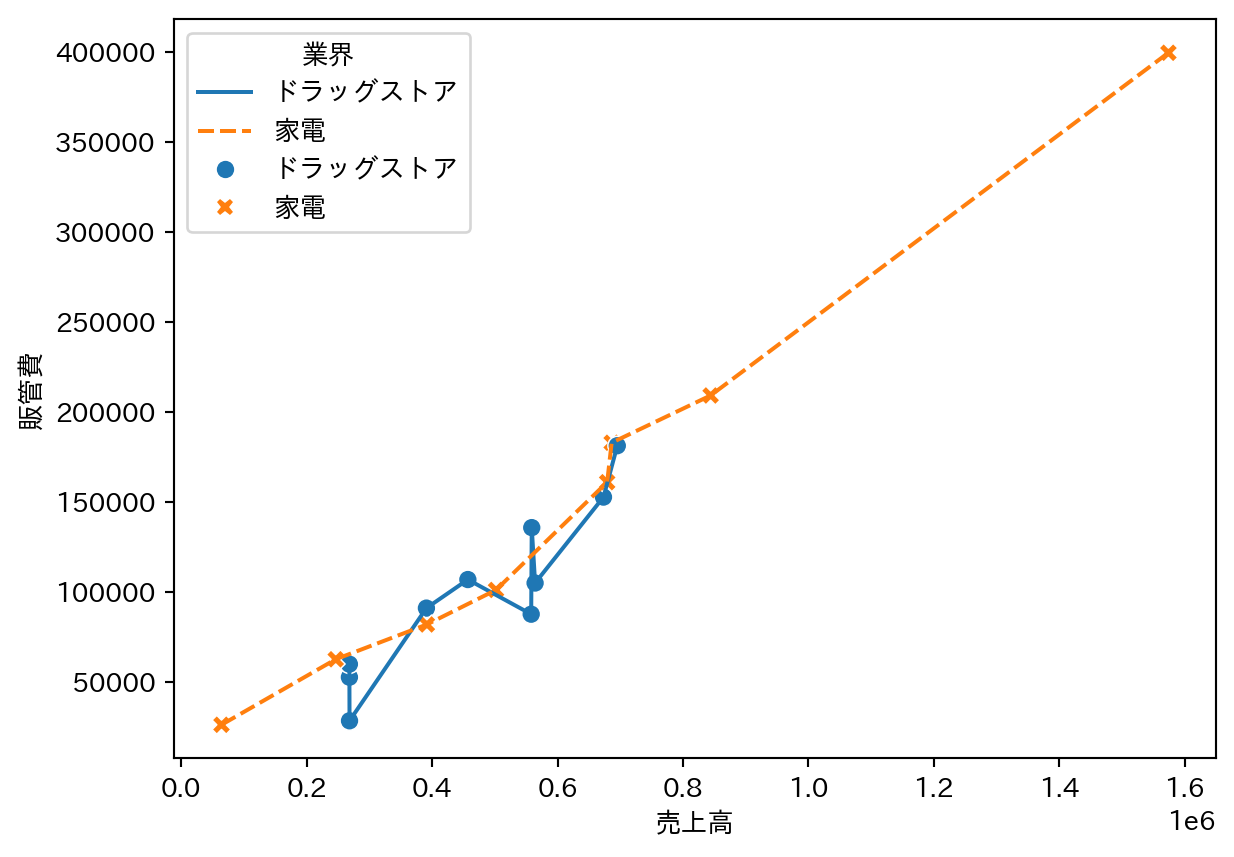
折れ線グラフだけだとデータの場所が分かりづらいので点もうつ sns.lineplotとsns.scatterplotを同じセルに書いて実行するだけ
sns.lineplot(
data=df_fin_ind,
x="売上高",
y="販管費",
hue="業界",
style="業界"
)
sns.scatterplot(
data=df_fin_ind,
x="売上高",
y="販管費",
hue="業界",
style="業界",
s=50
)
2グループの平均値の差が「偶然のばらつき」で説明できるのか、それとも真の差があるのかを統計的に検証する方法。ここではドラッグストアと家電量販店のROAに有意な差があるかを確かめる。
drug_df = df_fin_ind.loc[df_fin_ind["業界"] == "ドラッグストア"]
elec_df = df_fin_ind.loc[df_fin_ind["業界"] == "家電"]
scipy.stats.ttest_ind(drug_df["roa"], elec_df["roa"])TtestResult(statistic=np.float64(3.784858741407354), pvalue=np.float64(0.001623789557196223), df=np.float64(16.0))出力の pvalue が 0.05 より小さければ、2グループの平均値に統計的に有意な差があると解釈する。
2つの変数の間に線形の関係があるかを検定する。相関係数(-1 ~ 1)だけでなく、その相関がゼロかどうかの p 値も同時に得られる。
(
scipy
.stats
.pearsonr(
df_fin_ind["売上高"],
df_fin_ind["販管費"]
)
.correlation
)np.float64(0.9804563625540141)