7 重回帰分析
1 単回帰分析の問題点
1.1 単回帰分析の復習
- 問いを設定する
- ex. 在庫をたくさん抱えると業績が悪くなるのか
- この問いを直線の式 (\(y_{i,t} = \alpha + \beta x_{i,t} + \varepsilon_{i,t}\)) にする
- ex. \(\text{業績}_{i,t} = \alpha + \beta \text{在庫}_{i,t} + \varepsilon_{i,t}\)
- 「在庫をたくさん抱える」ところまで変数化していないことに注意する
- 「在庫」という変数は在庫の少ない企業も在庫の多い企業も含んでいる
もともとの問いを「在庫量は業績に影響するのか」に変換しているとも考えられる
- x, yのデータを集めて\(\alpha\)と\(\beta\)を推定する。
- 最小二乗法による推定
- \(\varepsilon\) の値が最も小さくなるように計算する(してくれる)
直線の式は以下の関係性を検証するためにある。
\[y_{i,t} = \alpha + \beta x_{i,t} + \varepsilon_{i,t}\]

1.2 交絡変数の問題
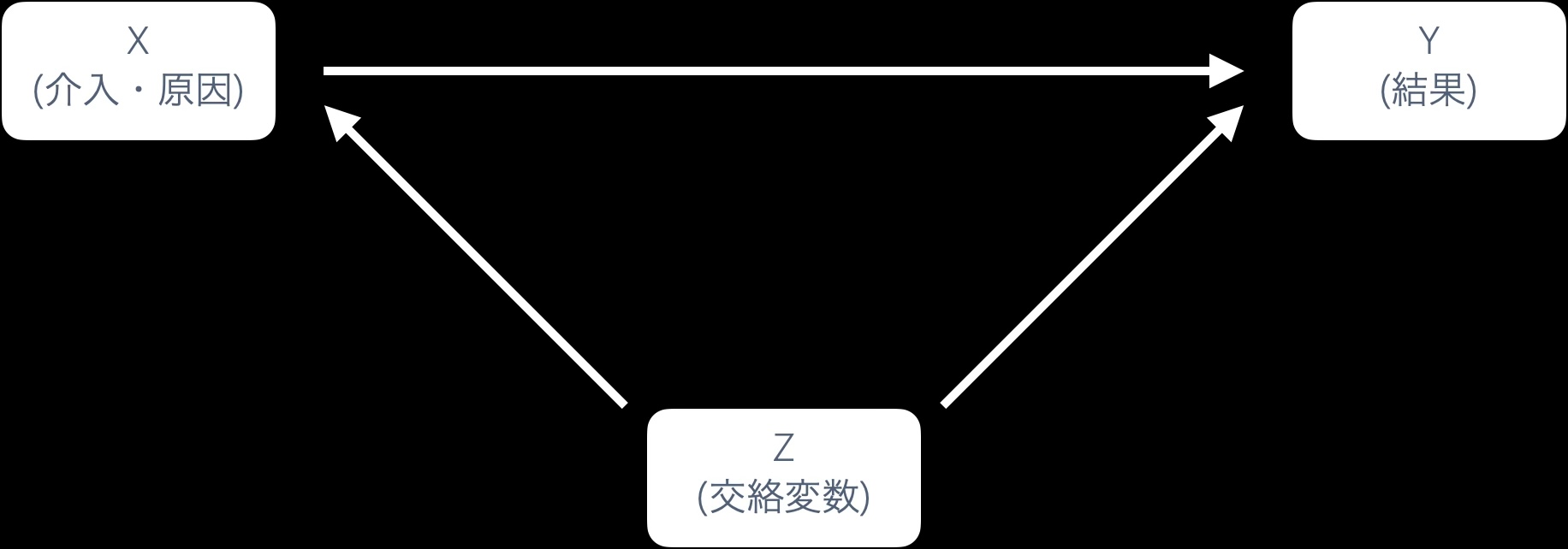
「棚卸資産が大きいほど売上原価が高い」という関係を見たとき、その関係は本当に棚卸資産が原因なのだろうか?
実は、企業の規模(売上高) が棚卸資産と売上原価の両方を同時に引き上げている可能性がある。大きな企業ほど棚卸資産も多く、売上原価も大きい。このような第3の変数を交絡変数という。
売上高(交絡変数)
↓ ↓
棚卸資産 → 売上原価(?)単回帰で「棚卸資産 → 売上原価」を推定しても、実は直線の式に含めていない売上高の効果が混入してしまっている。
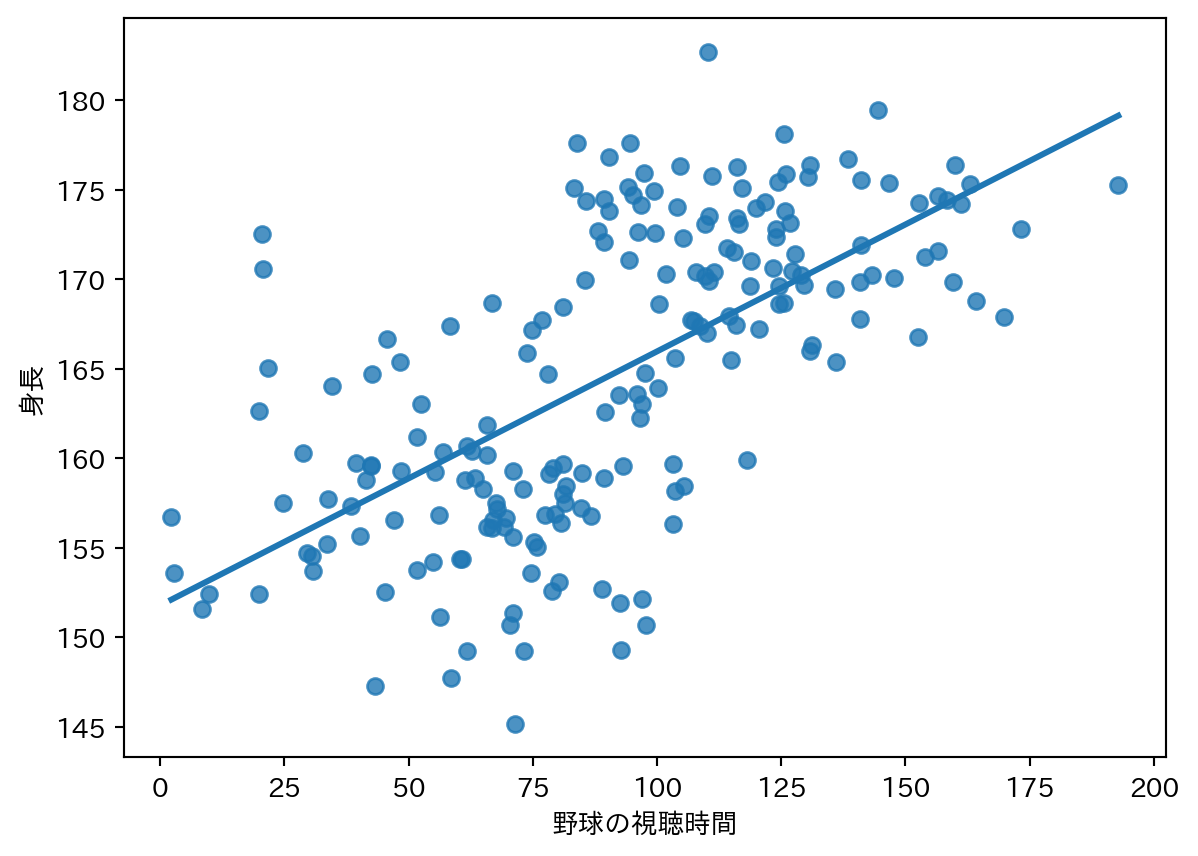
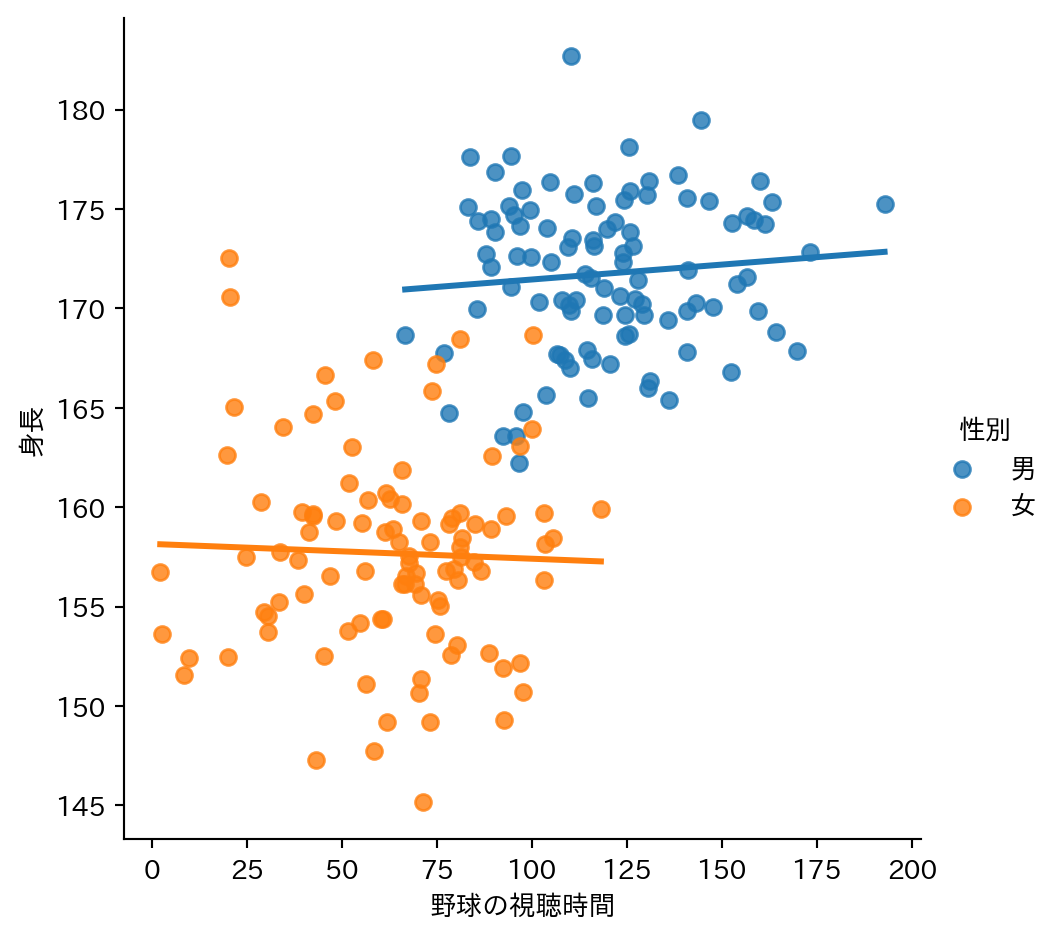
一見すると身長と野球の視聴時間に関係性があるように見えるが、性別という変数が交絡していた。
Important
z → x かつ z → y という関係性にあるzのことを交絡変数という。
1.2.1 重回帰分析の回帰式と交絡変数の例
- 式にすると:\(y_{i,t} = \beta_{0} + \beta_{1} x_{i,t} + \beta_{2} z + \epsilon_{i,t}\)
- 交絡変数を追加していくことで、どんどん条件付けできる
- 結果の見方:「条件が同じ時〜」という文句がつく
- ex. 従業員数(Z)が同じ時、AI(X)に投資したときの企業業績(Y)への影響は \(\beta_{1}\) である。
1.2.2 野球の視聴時間と身長
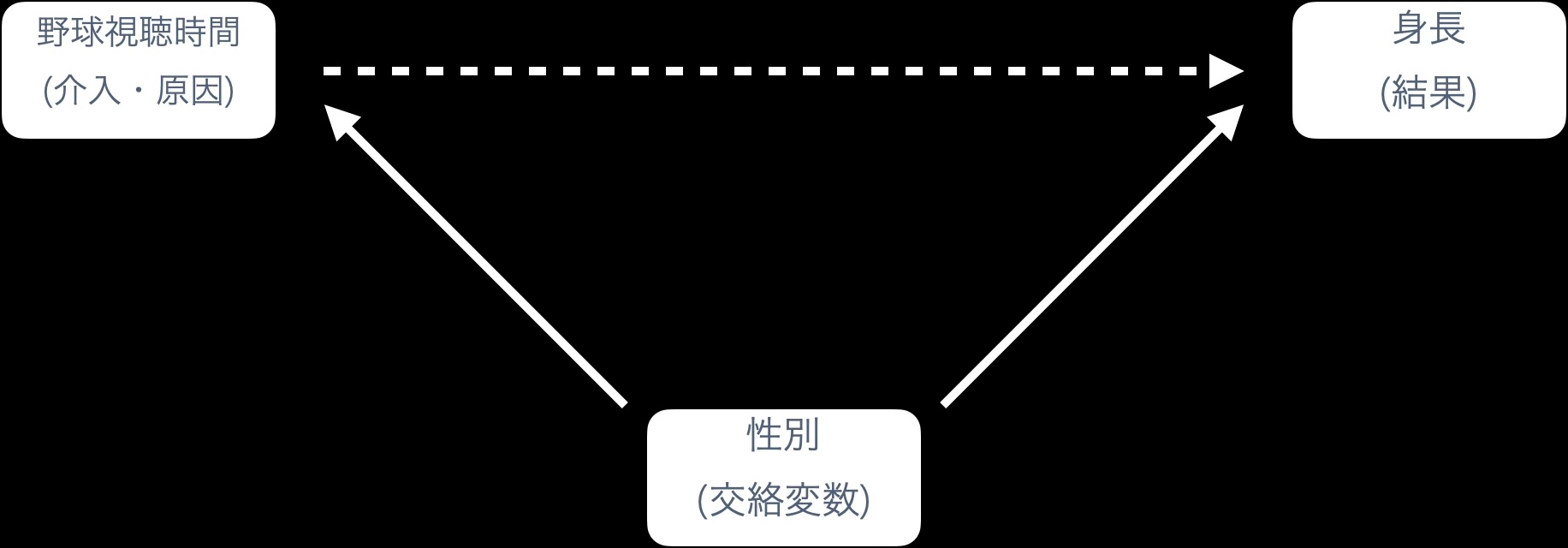
性別が同じなら、野球視聴時間がと身長に関係性があるとはいえない
1.2.3 マシュマロ我慢実験
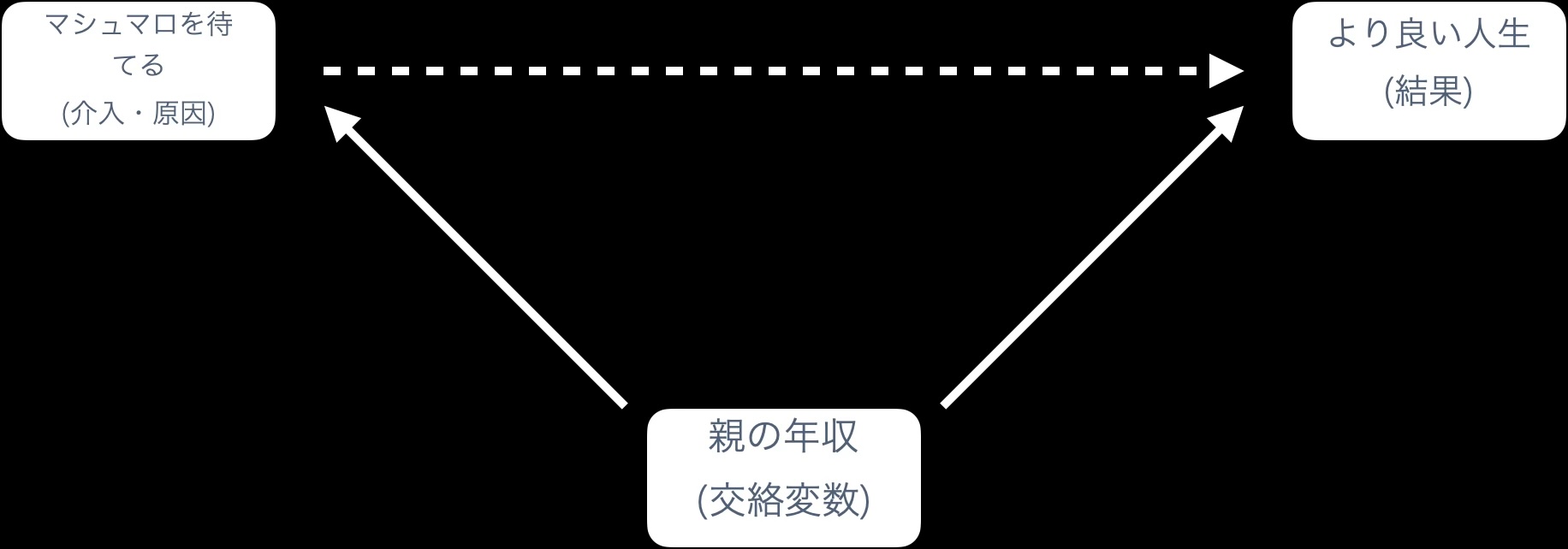
- 当初はSAT (大学進学適性試験)のスコア、教育達成度、ボディマス指数(BMI)、その他の生活指標で、我慢した子の方が優れているという結果が報告された。
- 大人の約束を信頼できる環境で育ったかどうかが影響していた
- 貧しい家庭では「今度買ってあげる」が実現しないことが多い
- → 子供は大人の約束を信頼しない
- → マシュマロを我慢しても約束が守られないと考える、だから食べる
- 貧しい家庭では教育にもお金をかけられず or 時間が取れず…
1.3 説明力の問題
そもそも、一つの要因 (x) でyの変動のすべて説明できることは少ない。いろいろな要因が重なり合ってyの値が決まる。
\(y_{i,t} = \alpha + \beta x_{i,t} + \varepsilon_{i,t}\) の \(\varepsilon\) (誤差項) にいっぱい情報が入っている状態だといえる。
1.4 実験の話
- 実験では調べたい一つの要素以外の条件を揃える
- ex. 日光が発芽に必要かどうかを調べたい
- → 日光の有無以外の条件を揃える (肥料、土の種類、水の量…)
実験のような環境で、分析者が他の条件を揃えられる or そういう条件のもとで集められたデータであれば単回帰でも問題ない。
社会科学において、ほとんどの場合そうではない。
1.5 ではどうするか
「条件を揃えたい」というのは同じ。回帰分析において条件を揃える方法がある。
それがコントロール変数を追加するというもの。
単回帰分析にコントロール変数を追加したら重回帰分析という。
2 重回帰分析
2.1 重回帰分析とは
\[y_{i,t} = \alpha + \beta_1 x_{i,t} + \beta_2 x2_{i,t} + \beta_3 x3_{i,t} + \dots + \varepsilon_{i,t}\]
複数の説明変数を同時に入れることで、「他の変数の値が一定のときのその変数の効果」を推定できる。「他の変数の影響を取り除いたときの、ある変数のyに与える効果」とも考えられる。交絡変数の影響を統計的に取り除けるのが重回帰の強み。
2.1.1 ブランド価値の例
ブランド価値を歴史という要素のみの単回帰分析で検証してみる。このとき、回帰式は
\[\text{ブランド価値}_{i,t} = \alpha + \beta \text{歴史}_{i,t} + \varepsilon_{i,t}\]
とできる。広告宣伝費や製品の質がブランド価値へ与える影響もあるはずなのに、これはどこへ行くのだろうか。これは \(\varepsilon\) や \(\beta\) に紛れ込む。
歴史ある企業が広告宣伝費を積み上げることでブランド価値へより大きな影響を与えるかもしれない。おなじように、歴史のある企業の製品の質が良ければブランド価値は一層高まるかもしれないし、製品の質が良ければ歴史が重ねやすいかもしれない。そういう重なっている影響は \(\beta\) に入る。歴史と関係ない部分は \(\varepsilon\) に入る。
ここで重要なのは2点ある。
1.明示されていない変数の影響 \(\beta\) に入ることをバイアスがあるという。バイアスがあるということは、本当は効果がないのに効果があるように見えたり、効果があるのに効果がないように見えたり、効果が過剰に見えたりする。
本当は \(\beta\) は歴史がブランド価値に与える影響を示すはずなのに、「歴史+広告宣伝費ちょっと」がブランド価値に与える影響を示すことになってしまっている。
2.誤差項に含まれる情報量である。今、広告宣伝費 + 製品の質が誤差項に含まれている。ここから広告宣伝費の情報を誤差項から抜き出せると、誤差項に含まれる情報量は製品の質だけになる(製品の質のデータがないのでその情報は抜き出せない)。
回帰分析で、誤差項から情報を抜き出すには直線の式に追加してやれば良い。
\[\text{ブランド価値}_{i,t} = \alpha + \beta_1 \text{歴史}_{i,t} + \beta_2 \text{広告宣伝費}_{i,t} + \varepsilon_{i,t}\]
このとき、\(\beta_1\) は「広告宣伝費が同じ時、歴史がブランド価値に与える影響」を意味し、 \(\beta_2\) は「歴史が同じ時、広告宣伝費がブランド価値に与える影響」
〇〇が同じ時 → 条件付け、コントロールとかを意味する。実験と同じである。
3 重回帰分析の実装
3.1 必要なパッケージを読み込んで、データも読み込む
Code
import pandas as pd
import statsmodels.formula.api as smfCode
df = pd.read_csv(
"drive/MyDrive/自分で作ったフォルダの名前/data.csv",
encoding="cp932"
)Code
df_clean = df.loc[
(df["棚卸資産"] <= df["棚卸資産"].quantile(0.99)) &
(df["売上原価"] <= df["売上原価"].quantile(0.99))
]3.2 pythonで重回帰分析
smf.ols の式に + で変数を追加するだけで重回帰になる。
Code
md_multi = smf.ols("売上原価 ~ 棚卸資産 + 売上高", data=df_clean).fit()
md_multi.summary2().tables[1].round(3)| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 10055.778 | 9762.578 | 1.030 | 0.320 | -10882.869 | 30994.426 |
| 棚卸資産 | -0.369 | 0.215 | -1.714 | 0.109 | -0.830 | 0.093 |
| 売上高 | 0.759 | 0.036 | 21.152 | 0.000 | 0.682 | 0.836 |
単回帰と比べて、棚卸資産の係数(coef)がどう変わったか確認する。
Code
md_single = smf.ols("売上原価 ~ 棚卸資産", data=df_clean).fit()
md_single.summary2().tables[1].round(3)| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 136448.211 | 42819.576 | 3.187 | 0.006 | 45180.446 | 227715.977 |
| 棚卸資産 | 3.523 | 0.617 | 5.708 | 0.000 | 2.208 | 4.839 |
規模感を調整する
Code
df["cogs"] = df["売上原価"] / df["総資産"]
df["inv"] = df["棚卸資産"] / df["総資産"]
df["sales"] = df["売上高"] / df["総資産"]
md_multi = smf.ols("cogs ~ inv + sales", data=df).fit()
md_multi.summary2().tables[1].round(3)| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -0.008 | 0.081 | -0.094 | 0.926 | -0.180 | 0.165 |
| inv | -0.508 | 0.230 | -2.204 | 0.044 | -0.999 | -0.017 |
| sales | 0.803 | 0.045 | 17.998 | 0.000 | 0.708 | 0.898 |
3.2.1 結果の表を出力する
ここでレポートや論文用の表形式に出力しとくと楽
出力結果をコピーしてwordやexcelに貼り付けたらそれっぽくなる
Code
# 前準備
!pip install stargazer
from stargazer.stargazer import Stargazer
import IPythonCode
stargazer = Stargazer([md_single, md_multi])
stargazer.show_confidence_intervals(True)
IPython.display.HTML(stargazer.render_html())| (1) | (2) | |
| Intercept | 136448.211*** | -0.008 |
| (45180.446 , 227715.977) | (-0.180 , 0.165) | |
| inv | -0.508** | |
| (-0.999 , -0.017) | ||
| sales | 0.803*** | |
| (0.708 , 0.898) | ||
| 棚卸資産 | 3.523*** | |
| (2.208 , 4.839) | ||
| Observations | 17 | 18 |
| R2 | 0.685 | 0.961 |
| Adjusted R2 | 0.664 | 0.955 |
| Residual Std. Error | 85922.924 (df=15) | 0.068 (df=15) |
| F Statistic | 32.579*** (df=1; 15) | 183.272*** (df=2; 15) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
4 重回帰の使い所
4.1 重回帰の使い所
重回帰分析は主に2つの目的で使われる。
- 決定要因の分析(何がYを決めているか)
- 経済的帰結の分析(Xが何に影響するか)
4.1.1 決定要因の分析(何がYを決めているか)
yの大小を説明する要因xがいくつか存在することを調べたいとき。
式にすると:\(y_{i,t} = \beta_{0} + \beta_{1} x_{1i,t} + \beta_{2} x_{2i,t} + \beta_{3} x_{3i,t} + \dots + \epsilon_{i,t}\)
例:「何がROAの大小を決めているか」→ 売上高利益率と総資産回転率をコントロールして分析する。

Code
md_roa = smf.ols("roa ~ 売上高利益率 + 総資産回転率", data=df_clean).fit()
md_roa.summary2().tables[1]| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -0.044877 | 0.011141 | -4.028113 | 1.245499e-03 | -0.068772 | -0.020982 |
| 売上高利益率 | 1.700519 | 0.113363 | 15.000612 | 5.086706e-10 | 1.457379 | 1.943659 |
| 総資産回転率 | 0.028751 | 0.005462 | 5.263821 | 1.197937e-04 | 0.017036 | 0.040467 |
決定要因の分析の例
- 企業等の奨学金返還支援(代理返還)制度導入企業
- どの企業がこの制度を導入しているのかは公開されている
- Q. どのような企業が導入しているのか? → 制度導入要因を分析する
- Aの候補:
- x1: 資金に余裕がある
- x2: 急成長中で資金に余裕ができそう
- x3: 若くて知名度が低い
- x4: 人手不足
\(\text{制度導入}_{i,t} = \beta_{0} + \beta_{1} \text{資金力}_{i,t} + \beta_{2} \text{成長性}_{i,t} + \beta_{3} \text{若さ(年齢)}_{i,t} + \beta_{3} \text{知名度}_{i,t} + \beta_{3} \text{人手不足}_{i,t} + \epsilon_{i,t}\)

使用するデータのイメージ
| 会社名 | 年度 | 制度導入 | 資金力 | 成長性 | 年齢 | 知名度 | |
|---|---|---|---|---|---|---|---|
| 0 | A社 | 2020 | 1 | 764 | -48 | 29 | 186 |
| 1 | A社 | 2021 | 1 | 839 | -59 | 44 | 31 |
| 2 | A社 | 2022 | 1 | 964 | -110 | 31 | 120 |
| 3 | B社 | 2020 | 0 | 721 | -11 | 22 | 48 |
| 4 | B社 | 2021 | 1 | 904 | 75 | 24 | 124 |
| 5 | B社 | 2022 | 1 | 747 | 13 | 15 | 93 |
| 6 | C社 | 2020 | 0 | 776 | 42 | 21 | 8 |
| 7 | C社 | 2021 | 0 | 966 | 95 | 26 | 146 |
| 8 | C社 | 2022 | 0 | 401 | 110 | 38 | 70 |
4.1.2 経済的帰結の分析(Xが何に影響するか)
- 「ROAが高い企業は純資産も大きいか」→ 規模(売上高)をコントロールして、ROA自体の効果を取り出す
- Q. 奨学金返済制度を導入したら人は集まるのか?
- Q. 健康経営に積極的だと業績が良いか?
- Q. 男性育休取得率が高いとまるまるが良い?
- Q. 買収前後でコスト構造が変わるか?
4.1.3 基本的に1つの検証で1つの原因だけ考える
式にすると:\(y_{i,t} = \beta_{0} + \beta_{1} x_{i,t} + \beta_{2} z_{1i,t} + \beta_{3} z_{2i,t} + \epsilon\)
- 基本的に1度の検証で1つの原因だけ考える
- 実験を思い出そう
- 知りたい条件以外の条件は揃える必要があった
- 条件を揃える = 数値がすべて一緒 → 式に含める意味がない
- これだと単回帰分析と一緒
- 実際は揃っていない
- 「条件付け・コントロール」してあげる必要がある
- → x以外の条件を揃える
Code
md_equity = smf.ols("純資産 ~ roa + 売上高", data=df_clean).fit()
md_equity.summary2().tables[1]| Coef. | Std.Err. | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 9598.957055 | 28337.183827 | 0.338741 | 0.739832 | -51178.257589 | 70376.171699 |
| roa | 263595.754883 | 295010.693141 | 0.893513 | 0.386685 | -369139.252559 | 896330.762326 |
| 売上高 | 0.196824 | 0.052881 | 3.722002 | 0.002276 | 0.083405 | 0.310243 |
説明変数を増やすと R-squared(決定係数)は上がるが、変数を闇雲に増やすのは禁物。理論的な根拠なく変数を追加すると解釈が難しくなる。
4.1.4 ex. 奨学金返還支援制度の導入とその結果
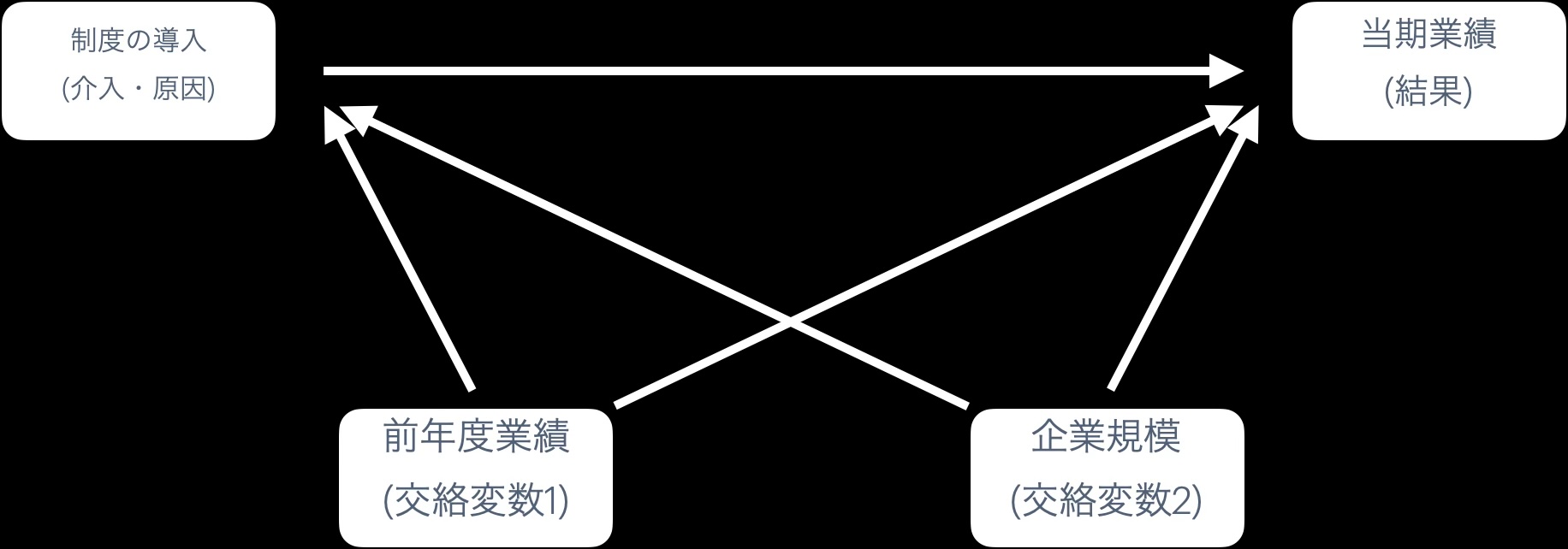
- 交絡変数の統制は効果をなくすのが目的ではない
- ここまでの例はバイアスを取り除くと効果が検出されなくなった。
- 交絡変数の統制はバイアスを取り除くところであり、
- 効果が検出されなくなったのは、たまたまそういう関係性だっただけだから。
- 前年度業績が良い企業は制度が導入できる余裕があり、当期業績も良くなりがち
- 企業規模が大きい企業は制度が導入できる余裕があり、当期業績も良くなりがち
4.2 単回帰分析から重回帰分析
4.2.1 単回帰の問題点
- 係数 \(\beta\) にバイアスが入る
- 交絡変数の存在
- 説明力が低い
- yはいろいろな要素で大小する
4.2.2 重回帰分析のとこ
決定要因のコントロール変数(x)が増える理由
要因が複数あるから
経済的帰結のコントロール変数(x)が増える理由
交絡変数を条件付けするから
共通
- 〇〇の要因や結果を検証するには〇〇をしていない側のデータも必要
- 結果は「x2(z1)の値が同じ時、x1が増えるとyが増える」とよむ
5 残された課題
5.1 残された課題
- 交差項(交互作用項)
- 相乗効果の検証
- 2次の係数 (\(x^2\))
- 大きくなる時めっちゃ大きくなる
- 固定効果
- 業種で条件付け、年度で条件付け